Archive Page 5
January 14th, 2018 by Ryan Hamilton
The structure of banks and finance firms are constantly changing as they evolve towards the structure best for todays environment. The trend over recent years has been for less traders and more engineers as expanded in this (article. (thanks Zak). In these posts I’ll describe the current state and where I think fintech, in particular market data capture and kdb are going.

(Newer firms that are) “Tech savvy, led by quants and data engineers rather than the expensive traders sitting on the scrap heap of most banks’ inferior tech, the new entrants now just need people with the skills to win over large numbers of customers.”
Banks as a Stack
Think of banks as a stack of services sitting ontop of each other [1]:

Communication within the system is mostly between the layers. Top layers rely on all the services of the layers beneath. e.g. A trader relies on a trading application, that relies on an internal web framework, that relies on a database, that relies on hardware. If we get more traders that need additional software changes, that could transmit down the stack into a request for more hardware. Communication outside the layer model, e.g. Sales asking for additional SAN storage is exceedingly rare.
Within the stack, I’ve highlighted in bold where market data capture sits. I believe most the points I’ll make can be applied wider to other areas within the stack but I’ll stick to examples within the area I know. Sometimes the “market data” team will include responsibility for Feeds, sometimes there will be a core team responsible for the database software they use, sometimes there won’t, but it captures the general structure.
Issues with the current Stack
Note each box on the diagram I refer to as a silo. A silo may be one team, multiple teams or a part of a team but generally it’s a group responsible for one area, looking after it’s own goals.
- Communication between silos is slow – Currently communication between silos consist of meetings, phone calls and change tickets. Getting anything done quickly is a nightmare. [2]
- Duplication of Effort – The simplified model above can often be heavily duplicated. e.g. FX, Equities, Fixed income may have separate teams responsible for delivering very similar goals. e.g. An FX Web GUI team, An equities Web GUI team. Losing all benefit of scale. [3]
- Misalignment of Incentives – Each silo has it’s own goals which often do not align with the overall goals of the layers above or below. e.g. The database team
may be experts in Oracle, even if an application team thinks MongoDB is the solution for their problem, the database team are not incentivised to supply/suggest/support that solution.[4]
- Incorrectly Sized Layers – At any time, certain silos or layers within the stack will have too many or too few resources. The article linked at the top of this post suggests the layers should be a pyramid shape, i.e. Very few sales/traders to meet todays electronic market needs. We should be able to contract/expand silos dynamically as required.
Possible Solutions coming in 2018
There are a number of possible solutions to the issues above available today, unfortunately I will have to expand on that in a future post. I am very interested in hearing others views.
Do you believe the stack and issues highlighted are an accurate representation? Solutions you see coming up? Either comment below or drop me an email.
I will hopefully post [part 2] shortly, if you want notified when that happens, sign up to our mailing list.
Notes:
- For some reason this reminds me of the OSI 7 layer model.
- Amazon try to escape this communication overhead by making everything an API
- Customers may prefer a bank that supplies all services but divisions within banks are too big to enforce conformity. Both limitations likely due to Dunbar Number
- Even within a single team, the modern workplace may create conflicting loyalties.
January 13th, 2018 by Ryan Hamilton
Notable events this year or possibly the previous year due to incoherent memory issues:
- KX went open on APIs – Improved and open sourced python, R, java and kafka interfaces.
- Java Driver – Got some new serialization functionality
- PyQ – KX acquired the rights
- The fusion/interface/machine-learning team at kdb promise to keep bringing improvements
- KX went to the cloud – There is now a cloud offering of kdb that is dynamically costed based on usage. It’s for existing customers only so far. Beta is available for personal use but kx may terminate access at any time. You can’t run it on third party “clouds”, no AWS I guess.and costs $0.10 per core <=4 cores, $0.05 per core >4 cores.
- Other users outside finance start to use kdb – It’s great to see and this probably flows from First Derivatives (FD) having purchased KX. However a number of them seem like proof of concepts pushed by FD to demonstrate it can be used. Hopefully in 2018 we will see more independently operating users.
- European Space Agency (ESA) – Al Worden an actual astronaut came to the London meetup with some great stories.
- Partnerships with redbull racing and marketing companies demonstrate possible growth opportunities
- Technical:
- Debugger with Stack Trace – You can now change the number of threads after startup
- uj/ij changes – A change in the behaviour of ij/lj joins means we now have ljf/ujf functions to provide historical equivalents. This is an old change but worth mentioning here as more people are only now upgrading from kdb 2.x
- Analyst – a jupyter notebook / tableau for kdb – KX launched an “analyst” product “a complete real time data transformation, exploration and discovery workflow. Using an intuitive point and click interface, the typical analyst can import, transform, filter, and visualize massive datasets without programming”
December 21st, 2017 by Ryan Hamilton
A quick post to highlight something a lot of people are bumping into with upgrades. The joins in 3.x for uj/ij and lj all changed how they treat nulls from the keyed table. In particular nulls now by default overwrite existing values. In the past nulls from the joining table did not overwrite and left the original value in the column. See the difference in the 3/three row shown below:
q)t:([] a:1 2 3; b:`one`two`three; c:1.0 2.0 3.0)
q)u:([a:2 3 4] b:`j``l; c:100 200 300.0)
q)t
a b c
---------
1 one 1
2 two 2
3 three 3
q)u
a| b c
-| -----
2| j 100
3| 200
4| l 300
q)t lj u / v3.x The null from u overwrites previous value in column b
a b c
---------
1 one 1
2 j 100
3 200
q)t ljf u / v2.0 or ljf - The original 3 value not overwritten by null
a b c
-----------
1 one 1
2 j 100
3 three 200
Other than the int/long indexing change this is one of the biggest breaking changes in migrating kdb 2.x to 3.x.
You may also enjoy our full kdb joins article.
April 13th, 2017 by Ryan Hamilton
qStudio 1.43 Released. This:
- Adds stack traces to kdb 3.5+
- Fixes the mac bug where the filename wasn’t shown when trying to save a file.
- Fixes a number of multi-threading UI problems
Download it now.
April 13th, 2017 by Ryan Hamilton
kdb+ 3.5 had a significant number of changes:
- Debugger – At long last we can finally get stack traces when errors occur.
- Concurrent Memory Allocator – Supposedly better performance when returning large results from peach
- Port Reuse – Allow multiple processes to listen on same port. Assuming Linux Support
- Improved Performance – of Sorting and Searching
- Additional ujf function – Similar to uj from v2.x fills from left hand side
kdb Debugger
The feature that most interests us right now is the Debugging functionality. If you are not familiar with how basic errors, exceptions and stack movement is handled in kdb see our first article on kdb debugging here. In this short post we will only look at the new stack trace functionality.
Now when you run a function that causes an error at the terminal you will get the stack trace. Here’s a simple example where the function f fails:
Whatever depth the error occurs at we get the full depth stack trace, showing every function that was called to get there using .Q.bt[]:
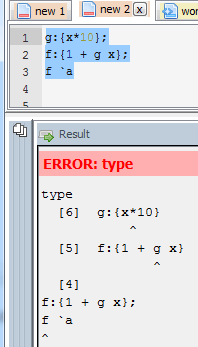
The good news is that this same functionality is availabe in qStudio 1.43. Give it a try: qStudio.
Note: the ability to show stack traces relies on qStudio wrapping every query you send to the server with its own code to perform some analysis and return those values. By default wrapping is on as seen in preferences. If you are accessing a kdb server ran by someone else you may have to turn wrapping off as that server may limit which queries are allowed. Unfortunately stack tracing those queries won’t be easily possible.
That’s just the basics, there are other new exposed functions and variables, such as .Q.trp – for trapping calls and accessing traces that we are going to look at in more detail in future.
February 27th, 2017 by Ryan Hamilton
qUnit has added a new HTML report to allow visually easily seeing the difference between expected kdb results and actual results. To generate a report you could call:
.qunit.generateReport[.qunit.runTests[]; `:html/qunit.html]
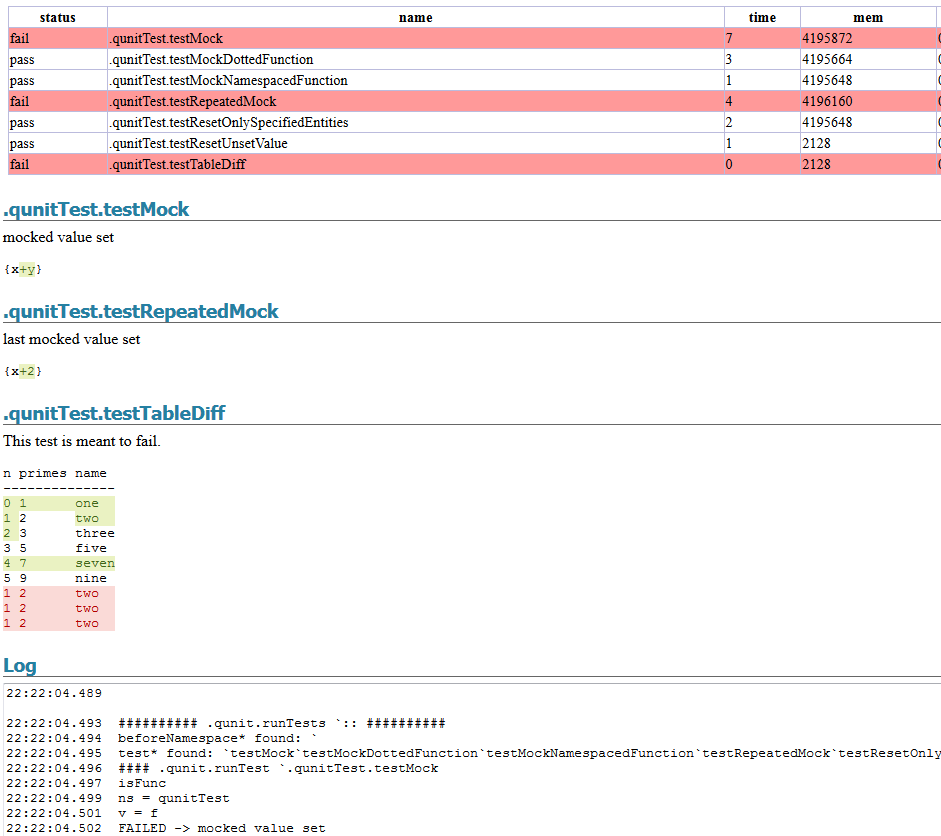
It’s also added a
.qunit.assertKnown[actualResult; expectedFilename; msg]
call to allow comparing an actual results to a file on disk. While allow easy updating of that file and avoiding naming collisions.
February 7th, 2017 by Ryan Hamilton
Download the latest qStudio now.
qStudio Improvements
- Bugfix Sending empty query would cause qStudio to get into bad state.
- Default to chart NoRedraw when first loaded to save memory/time.
- Preferences Improvements
- Option to allow saving Document with windows \r\n or linux \n line endings. Settings -> Preferences… -> Misc
- Allow specifying regex for folders that should be ignored by the “File Tree” window and Autocomplete
- Add copy “hopen `:currentServer” command button to toolbar.
- Ctrl+p Shortcut – Allow opening folders in explorer aswell as files.
- Smarter Background Documents Saving (30 seconds between saves on background thread)
sqlDashboards Improvements
- Allow saving .das without username/password to allow sharing. Prompt user on file open if cant connect to server.
- Bugfix: Allow resizing of windows within sqlDashboards even when “No table returned” or query contains error.
- If query is wrong and missing arg or something, report the reason.
- Stop wrapping JDBC queries as we dont want kdb to use the standard SQL handler. We want to use the q) handler.
February 7th, 2017 by admin
This post is a walkthrough of my implementation in Q of the RosettaCode task ‘Death Star’.
The code is organized as general-purpose bitmap generator which can be used in other projects, and a client specific to the task of deathstar-drawing. The interface is a function which passes a map of pixel position to pixel value. The map can be a mapping function, or alternatively a 2D array of pixel values. The bitmap generator raster-scans the image, getting pixel values from either a mapping function or a mapped array.
genheader follows directly from the referenced BMP Wikipedia article.
genbitmap and genrow perform a raster scan of the image to be constructed. genbitmap steps along the vertical axis, calling genrow, which steps along the pixels of the current line, in turn calling fcn, the pixel-mapping function passed in by the client.
A sample client is included in comments, the simplest possible demonstration of shape and color (a circular mask selecting between two fill colors):
Conveniently, functions and arrays can be equivalently accessed in Q.
Here is an array-passing client which replicates the first example in the Wikipedia article on BMP format.
Element ordering can be confusing at first glance: Byte order for RGB pixels is B,G,R. Also, rows are indexed from bottom to top, and since bitmaps are in row-major order, the first and second array indices designated x and y correspond to the y and x image axes respectively.

After centering the image fcn applies several masks:
is calculates the orientation of a point on a sphere, and then a pixel value for that point, using the dot product of l, the light source direction, and s, the surface orientation. A correction of (1+value)/2 is applied, to achieve the ‘soft’ appearance of a space object in a movie. Alternatively we might have suppressed negative illumination values, to get the high-contrast appearance of an actual space object.
We might want to generate images of the death star at different rotations, however due to some simplifying assumptions we can’t rotate the weapon face to the side without glitching. We calculate z1 and z2 to select between the forward surface of the death star and the rearward surface of the weapon face. We should also calculate z3, the forward surface of the weapon face sphere, and z4, the rearward surface of the death star:
z3:170+z[x2;y;r];
z4:-z1;
Then the masks can be modified so that when z3 > z1 > z4 > z2, an additional bit of background is visible through the carved-out chunk of the deathstar.
TODO: discuss limitations of mask-and-fill; alternative approaches; display-list; …
TODO: discuss animation; …
TODO: discuss three-component architecture: orchestrator, world, bitmap generator
TODO: … conclusions
July 19th, 2016 by admin
I often get asked what open source alternatives are there to kdb+. The answer depends on what you are trying to do. IF there was a product XYZ that provided some similar features, whether it can replace kdb depends on a few issues:
>>”What will XYZ bring us that kdb doesn’t?”
Kdb has been tried and tested over many computer/man-years. The KX team have fixed 1000’s of edge cases, optimization issues and OS specific bugs. Any similar system would have to replicate a lot of that work. Possible but it would take time and teams actually using it. It would also require a corporate entity to provide support and bug fixes together with long term guarantees of availability (not a few part-time committers on github). Ontop of that it would need to deliver more value to make it worth switching.
Kdb is both a database and a programming language and it’s that combination which I believe gives kdb it’s unique power:
– There is no open source database that provides the speed kdb provides for the particular queries suited to finance.
– Combining kdb and basing queries on q-sql/ordered lists (rather than set theory for standard sql) means queries require fewer lines of code. I believe this expressiveness combined with longer term use of kdb/q changes how you think and allows easily forming queries which many people couldn’t begin to write in standard sql.
– However as much as I think q is a selling point of kdb, I know many others would disagree. It takes a reasonable period of time to convince someone non-standard SQL is beneficial.
What is your use case? e.g. Example Queries to Consider:
1. Select top N by category
http://stackoverflow.com/questions/176964/select-top-10-records-for-each-category
select n#price by sym from trade
2. Joining Records on nearest date time:
http://www.bigresource.com/MS_SQL-joining-records-by-nearest-datetime-XsKMeH3t.html
aj[`sym`time;select .. from trade where ..;select .. from quote]
3. Queries dependent on order. (eg price change, subtract row from previous)
http://stackoverflow.com/questions/919136/subtracting-one-row-of-data-from-another-in-sql
select price-prev price from trade....
XYZ would need to support these queries well. Why would I chose XYZ instead of Python/R/J/A+?
Existing (some similar languages) that offer a larger existing user base, more libraries and a proven/stable platform. Unless a way is found to leverage existing languages/libraries XYZ will be competiting for attention against kdb and also python/numpy/julia etc.
>>”bring in the cost factor and should XYZ be considered as a big future player?”
For the target market of kdb the cost is often not the most significant factor in the decision. If kdb can answer questions that other platforms can’t or in a much shorter time, it often adds enough value to make the cost irrelevant. In fact many large firms are happy paying a pricey support agreement for free open source software so that they have someone to (blame) call to resolve an issue quickly.
>>”but could XYZ catch up and begin to be trusted by bigger institutions?”
If XYZ started to be able to answer the three example queries shown above at a reasonable speed multiple perhaps but I consider it unlikely. Kdb is entrenched and for its target use case it is currently unbeatable. Some people may have use cases that don’t need the full power of database and language combined or have other important factors (cost,existing expertise). I think those use cases have viable open source solutions.
June 25th, 2016 by Ryan Hamilton
qStudio 1.41 is now available to download.
It adds the ability to use custom Security Authentications and custom JDBC drivers.
By automatically loading .jar plugins from libs folder.
After a few users reported issues around “watched expressions” we are removing the ctrl+w shortcut as it was often getting used by mistake. The last change was some internal work to improved startup/shutdown logging for debugging purposes..