Kerf - the new column oriented database
Kerf is a recently released time-series database. As part of the launch process I've been setting up test installations and answering questions from people new to the product. One of the things people seem to want to know the most about Kerf is whether it can handle sending large volumes of data over the network. The answer is yes, Kerf was built from the ground up to do this, and I'll show a few different ways to send a lot of data.
Note: This article is a guest post by Kevin Lawler lead developer of Kerf.
Contents
- Getting Started - Running a server
- Sending Data
- Why you should try Kerf
Getting Started
You can send data to Kerf from other programs and languages, of course, but to keep things simple for this demo we'll be sending data from one Kerf instance to another. If you want to execute the commands along with the demo, you can get a copy of Kerf for your platform at https://github.com/kevinlawler/kerf. The first thing that we'll do is get a connection going from one Kerf instance to another. Inside of a terminal type:
./kerf -p 1234
This will start a terminal running on port 1234. If you operating system asks for permission to open a port you'll need to grant it. Then open another terminal, or another tab within your terminal, and launch a client by typing simply.
./kerf
This will launch the client. Note that you don't need to specify a port for the client.
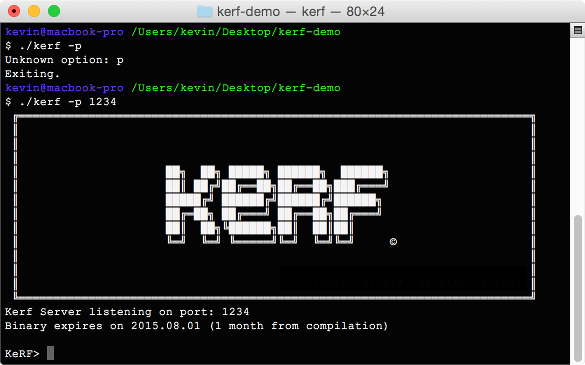
At this point our server is waiting patiently with an open port and our client hasn't done anything. We're going to make them talk to each other.
Sending Data
- First the client has to open a connection to the server. Do this by executing the command:
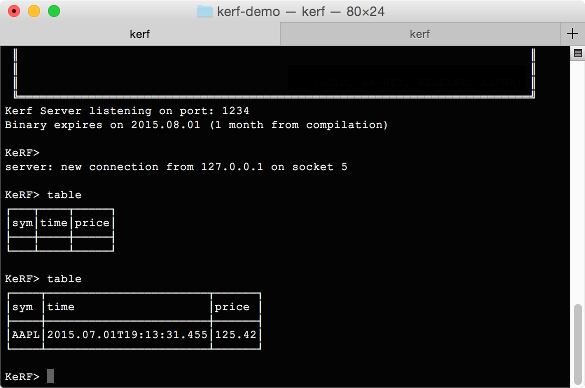
open_socket - Next we'll create an empty table on the server. This table will have a special enumerated column for storing symbols
- Finally we perform a single insert into the empty table.
If we switch to the server instance and check, we should see a table has been created inside the variable "table". The table has one row with a price for Apple.
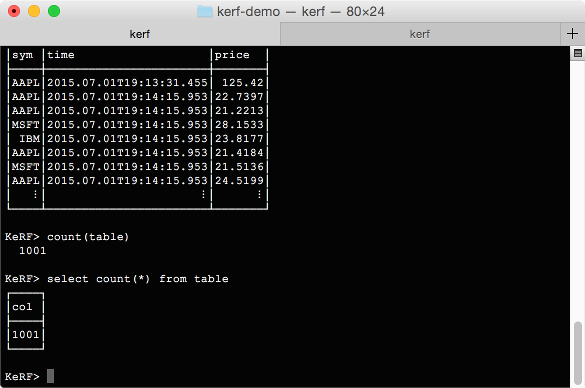
Now we can get a little more adventurous. Why don't we repeat that single send 1,000 times, and fill the table with random data? Run the following command all as one line:
Inside of the server, we can use "table" to review the table, or "count(table)" to verify that it is the correct size. If you prefer SQL, you can even use "select count(*) from table".
This method of sending tick data works, but it is not ideal. We are are sending messages one at a time. One thing we might try that's better is to group our values together and send our columns in batch. Here's how we can do that. Note that this time we're using double-brackets "{{" and "}}" in our insert expression.
Sending the columns like this is good, but there's an even better way. We can send an entire table by itself. To end the demo we'll send a table directly from one instance to another. When the server receives the table it will attach it to the end of the existing table. This is the most efficient way of transmitting data.
Kerf Client - Server Communication
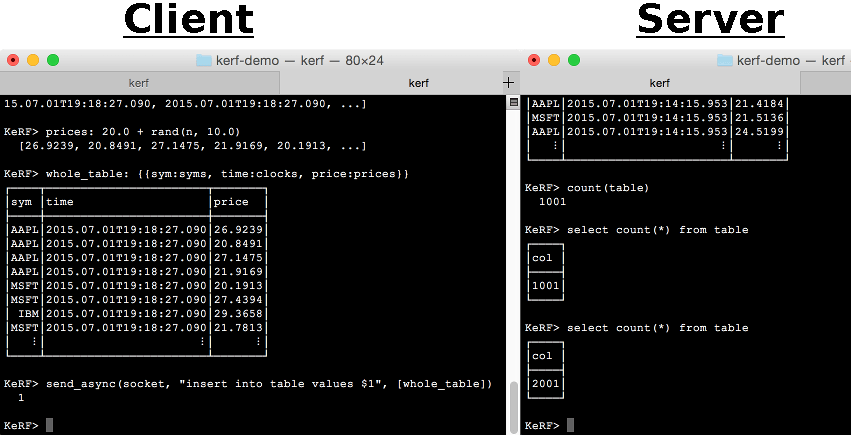
You can experiment by increasing the size of n and by sending data from one computer to another instead of across the same host. Kerf takes a new approach to handling tick data. There's no reason being fast should sacrifice usability.
Why you should try Kerf
As you have seen, starting a Kerf database and sending data from one process to another is simple. Kerf simplifies a lot of other tasks when dealing with large amounts of tick data.
As well as network transmission, Kerf:
- Provides tools for dealing with real-time and historical databases
- Is good at processing logfiles
- Has methods for creating continually indexed columns and enumerated columns
- One unreleased features is "NoSQL" tables, for schemaless and unstructured tick data at scale.
For more on Kerf please visit our github page or contact Kevin Lawler.
This article was authored by Kevin Lawler, who is the tech lead on Kerf.
Kevin's last adventure was Permanent, a spreadsheet app for iPad. He's also built Kona, which is an open-source implementation of K. Kevin's other open-source projects are available on his his GitHub page.