
 PeachQ
PeachQ
MIT-licensed open source q. An early preview you can try in the browser.
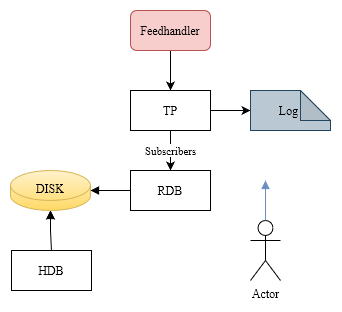
How are we going to scale and deploy Tick?
Problem: Reasonably allowing multiple databases
Very early on you will need to make some long term decisions. I’m not going to try and say what is best as I don’t believe that’s possible. What I would like to suggest is a framework for deciding. As a team, rather than arguing A against B. Try to decide what parameters would cause a tipping point.
Considering Storage
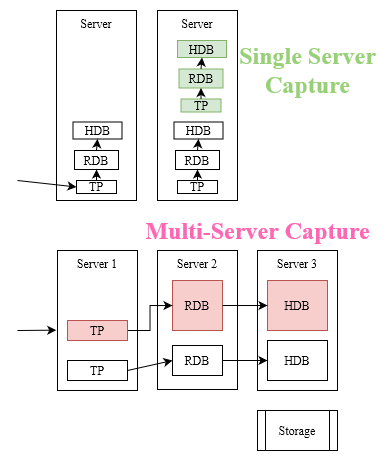
Problem: You scaled out but now you can’t manually jump in and fix issues yourself. You need to automate improvements to the core stack.
These are issues that everyone encounters and there are well documented solutions.
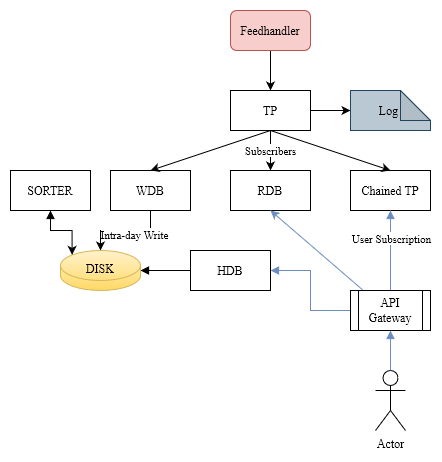
Problem: We scaled out even further and now processes are everywhere
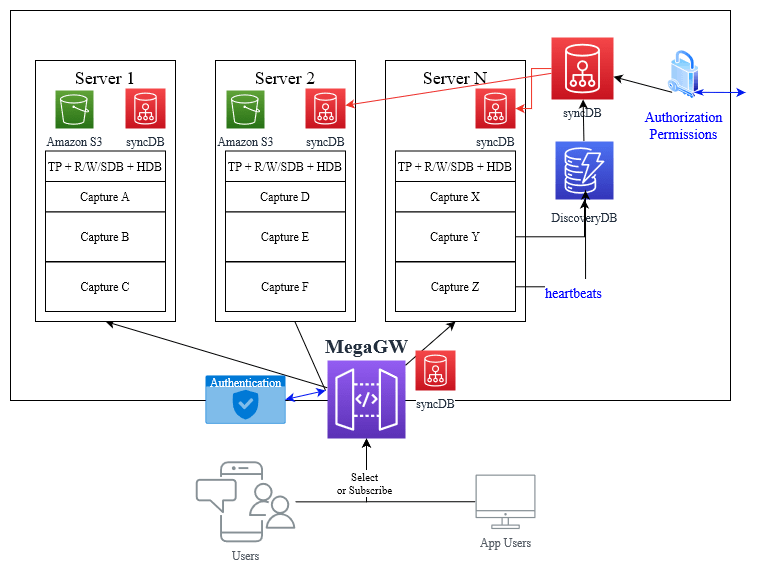
For many reasons we need to know where all components are running and we need that info to be accessible. Let's introduce two components to achieve that:
My preference is to use kdb as it seems well suited and the team has expertise. So now when every process starts it will send a regular heartbeat to one or more discovery databases. On a separate timer, the DiscoveryDB will publish the list of existing services to syncDB.
Will have a master process, that then sends updates to all servers and downstream processes. When any capture on a server wants to query a sync setting, it calls the API which looks at the most local instance only. It’s designed to NOT be fast but to be hyper reliable. We are not spinning up/down instances every minute. These are mostly databases that sit on large data stores so caching them for long periods is fine. Worst case we query a non-existant server and timeout. What we don’t do is delete or flush the cache.
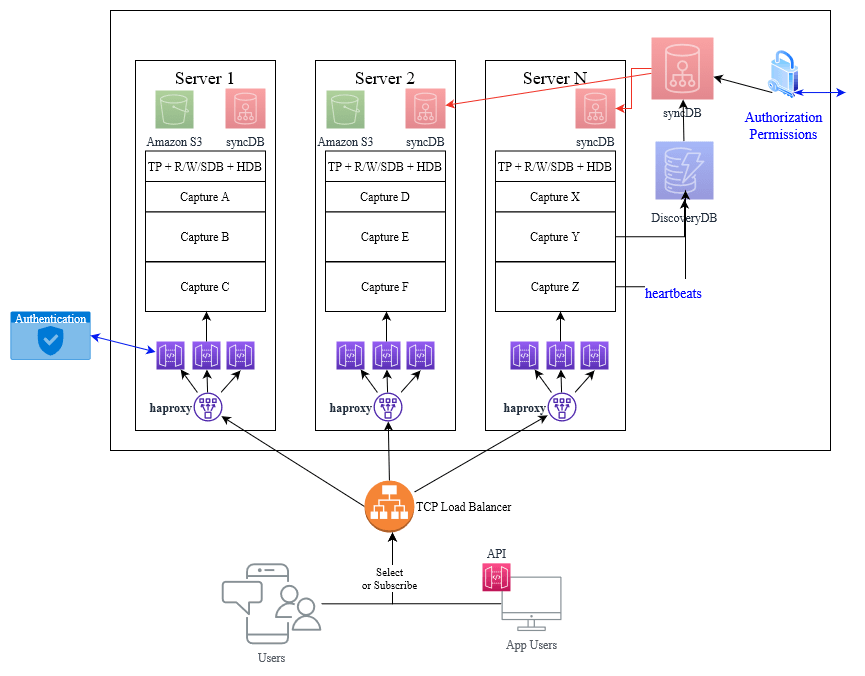
It can take a user query, see where it needs sent to, send queries to that location and return the result. We can make one process like that but how do we scale it up to 100s of users while looking like one address? I don’t have time to go into every variation I’ve seen or considered so I’ll just show one possibility:
Starting from the User Query:
The nice thing here is that we’ve used off-the-shelf components, there is NO-CODE. The best code is no-code. The load balancers only knows it’s forwarding connections. Meanwhile we can program the MegaGW as if it’s just one small component. It will behave to the user exactly like a standard q process, meaning all the existing API and tools like QStudio will just work.
MIT-licensed open source q. An early preview you can try in the browser.