Kdb Table Attributes
Attributes allow describing or applying data structures to lists to allow queries to run faster. When applied well they take advantage of the data itself in other cases you will want to rearrange your database so that they can be applied. In some cases extra information will be created to speed lookup and this will increase memory usage.
| Attribute | Requires | Description | Space |
|---|---|---|---|
| `s# Sorted | Elements be sorted | By marking the list as sorted, binary search can be perfomed instead of fully scanning the column, speeding up many operations. | None |
| `u# Unique | Elements be unique | Marks list as unique and creates a unique hash table in the background, allowing constant time lookup of elements. | Large |
| `g# Grouped | - | Attribute that is closest to indexing in standard databases, a lookup table from each distinct value in the table is created to map to the positions where that value occurs. Allowing much quicker lookup of them entries. | Largest |
| `p# Parted | All elements of same value occur one sequential block. | By storing the same items continuously on-disk reading using standard hard drives is much faster. | Small |
Applying Attributes
All attributes can be applied to lists that meets that attribute's requirements. Since columns of a table are themselves lists, attributes can be applied to them. The three formats for applying attributes are:
- l:`s#2 4 7 9 - Specify during list creation
- @[`.; `listl; `s#] - Functional apply, i.e. to the variable list l in the default namespace `. apply the sorted `s# attribute.
- update `s#time from `t - update a table to apply the attribute.
Once you have applied an attribute you can check that it has worked by typing the variable into the console and seeing that it is shown or by using the attr function. For tables you can call meta to see the columns attributes.
`s# Sorted Attribute
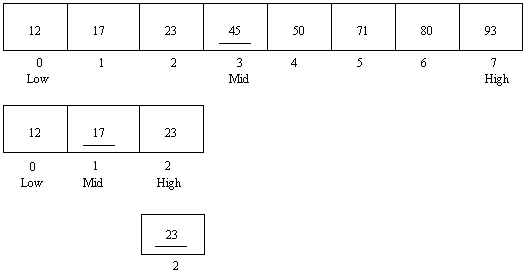
The sorted attribute is applied to a list or column to specify that the data is sorted in ascending order. When kdb knows a list is sorted it can perform binary search to find elements rather than scanning the entire list. Below is an illustration of the steps of a binary search for the number 23 in a numeric vector. At each stage you check the middle of the search area and then narrow the search to the half where the number must occur.
The below code illustrates a number of important points:
- Applying the `s# attribute using list:`s#list
- The `s# attribute is only maintained during appends that maintain the sorted requirement, otherwise it is lost.
- An s-fail error will occur if you try to apply the attribute to an unsorted list.
Now that we can create lists with the sorted attribute we can examine the benefits.
In kdb the question mark can be used to find an element within a list using the syntax list?element for a
list of numbers it will return the index where that number occurs. We are going to create two lists, one marked with the sorted attribute (l), the other not (k).
Then we will examine the time taken to lookup elements at various positions in the list using find-?.
For the plain list, the further towards the end that the element occurs the longer it is taking for
find-? to complete.
The find-? operator is scanning the entire column for the element, therefore searching the plain list takes time proportional to the length of the list.
In contrast the timings for find-? within the sorted list are too small to be significant.
(For those interested search time is proportional to log(listSize), see here for why).
Although we only show the timings for find-? the speedup shown also applies to tables and operators that apply there including: max, min, col=val, within.
`u# Unique Attribute
The `u# attribute marks a list as unique and creates a unique hash table in the background, allowing constant time lookup of elements. The data that `u# is applied to MUST contain only unique elements, no value can be repeated. We will receive a 'u-fail if you try to apply the attribute to a list where all the elements are not unique. Like `s# the unique attribute provides significant speedup for finding elements as shown in the code below, however unlike `s# it also requires extra storage space.
`g# Grouped Attribute
Suppose a table contains n rows and we want to retrieve all those with ticker=`YAHOO, one possibility would be to scan the entire ticker column and find all occurrences. Scanning the entire coumn would take time proportional to n. Alternatively we could store a lookup table from unique tickers to all the positions where that records occurs. Rather than performing a full column scan we can jump straight to only the desired indices, lookup is now proportional to the number of unique elements, providing a significant speedup. This is what the grouped attribute `g# does, it is similar to a dense index from a standard SQL database. `g# is particularly useful as it does not enforce any requirements on the data, however it does require significant storage space and there is a hard limit to how many grouped columns kdb supports. Here is a demo of `g# together with how it would be stored in the background:
`p# Parted Attribute
The parted attribute marks a list as having all occurrences of a value occuring in a sequential block. This allows the creation of a lookup table from each distinct value to its first occurrence, then all occurrences of that value can be found in one sequential read. It is particularly useful for on disk data as with hard disk drives seek time to find a data location is significant but once the location is found the data transfer rate is high. Here is an example of it being applied:
As demonstrated `p# is not preserved even during appends that would meet the requirements, therefore you must be particularly careful with parted data.
The restriction upon data is particular cumbersome, a table can only realistically have one column with the parted attribute applied.
Typically in a kdb+tick database, the data is partitioned by date then parted by sym. This allows queries such as:
select from trade where date=2011.01.02,sym in `A`B
To open just the needed partition and to instantly jump to the selected syms and read their data from disk sequentially.
Since sorting all data to have the same values positioned in sequential blocks takes a long time, an end of day process converts todays data down for storage giving the necessary time.
Example Speed benefit and Space cost
For the case of a list with totally unique integers the access timings and size of data structure required are considered below. For grouped and parted this is obviously a worst case scenario for space usage and this is reflected in the space required.
Applying Attributes to Tables
Once we understand the concept of attributes, applying them to tables to speedup queries is simple. below we consider two queries:
select count i from t where dt=2015.01.03
select avg price from t where sym=`C
We will consider their behaviour when table t has a)no attributes b)`s# attribute on dt c)`g# attribute on sym:
Query running times
| Attributes | Query Time: select count i from t where dt=2015.01.03 | Query Time: select avg price from t where sym=`C |
|---|---|---|
| None | 2196 | 7837 |
| `s# on dt | 3 | 7795 |
| `s# on dt and `g# on sym | 5 | 1428 |
The total running time for both queries is now 1.433 seconds, down from 10.33, i.e. 14% of the original time. This simple demonstration, shows how attributes can be applied to tables and the significant speed benefits they provide even for this small data set.
On our three day kdb training courses this is one of the topics we cover in depth and then work through exercises to give attendees the knowledge on how best to structure their database. We believe our course is one of the fastest ways to learn kdb well, if your interested check when our next course is.