Archive for the 'kdb+' Category
December 10th, 2013 by Ryan Hamilton
In a previous post I looked at using the monte carlo method in kdb to find the outcome of rolling two dice. I also posed the question:
How many people do you need before the odds are good (greater than 50%) that at least two of them share a birthday?
In our kdb+ training courses I always advise breaking the problem down step by step, in this case:
- Consider making a function to examine the case where there are N people.
- Generate lists of N random numbers between 0-365 representing their birthdays.
- Find lists that contain collisions.
- Find the number of collisions per possibilities examined.
- Apply our function for finding the probability for N people to a list for many possibilities of N.
In kdb/q:
Plotting our data in using qStudio charting for kdb we get:
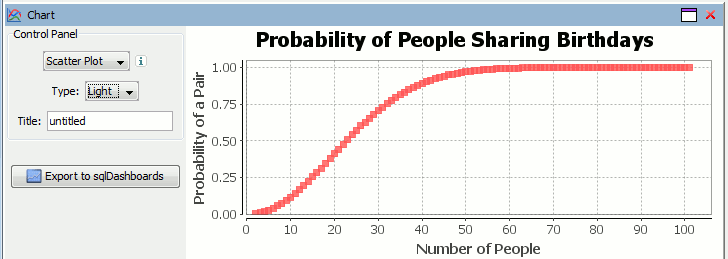
Therefore as you can see from either the q code or the graph, you need 23 people to ensure there’s a 50% chance that atleast 2 people in the room share a birthday. For more details see the wikipedia page. This still leaves us with the other problem of finding Pi using the monte carlo method in kdb.
December 3rd, 2013 by Ryan Hamilton
 Performing probability questions in kdb/q is simple. I recently got asked how to find the probability of rolling a sum of 12 with two dice. We’ll look at two approaches to finding the likely outcomes in kdb/q:
Performing probability questions in kdb/q is simple. I recently got asked how to find the probability of rolling a sum of 12 with two dice. We’ll look at two approaches to finding the likely outcomes in kdb/q:
Method 1 – Enumeration of all possibilities
Step by step we:
- Generate the possible outcomes for one die.
- Generate all permutations for possible outcomes of two dice, find the sum of the dice.
- Count the number of times each sum occurs and divide by all possible outcomes to get each probability.
Method 2 – Monte Carlo Simulation
Alternatively , if it hadn’t occurred to us to use cross to generate all possible outcomes, or for situations where there may be too many to consider. We can use Monte Carlo method to simulate random outcomes and then similarly group and count their probability.
q)1+900000?/:6 6 / random pairs of dice rolls
2 5 6 6 2 4 3 1 5 1 1 4 6 5 3 4 2 4 1 2 3 6 6 1 1 3 6 3 6 2 3 1 5 4 4 4 6 3 1 3 1 2 5..
4 4 4 5 1 4 3 6 5 1 4 4 3 4 1 1 1 5 4 5 2 4 4 4 5 2 1 2 6 5 2 4 3 1 4 2 1 1 3 4 6 5 1..
q)/ same as before, count frequency of each result
q)(2+til 11)#{x%sum x} count each group sum each flip 1+900000?/:6 6
2 | 0.02766
3 | 0.05559
4 | 0.08347
5 | 0.11085
6 | 0.1391822
7 | 0.1669078
8 | 0.1386156
9 | 0.1112589
10| 0.08317222
11| 0.05556222
12| 0.02773111
Therefore the probability of rolling a sum of 12 with two dice is 1/36 or 0.27777. Here’s the similar dice permutation problem performed in java.
Kdb Problem Questions
If you want to try using the monte carlo method yourself try answering these questions:
- The Birthday Paradox: How many people do you need before the odds are good (greater than 50%) that at least two of them share a birthday?
- Finding the value of Pi. Consider a square at the origin of a coordinate system with a side of length 1. Now consider a quarter circle inside of the square, this circle has a radius of 1, therefore its area is pi/4. For a point (X,Y) to be inside of a circle of radius 1, its distance from the origin (X ², Y²) will be less than or equal to 1. We can generate random (X,Y) positions and determine whether each of them are inside of the circle. The ratio of those inside to outside will give the area. (bonus points for using multiple threads)
November 12th, 2013 by John Dempster
qStudio is an IDE for kdb+ database by kx systems that allows querying kdb+ servers, charting results and browsing server objects from within the GUI.
Version 1.29 of qStudio is now available:
http://www.timestored.com/qstudio/
Changes in the latest version include a new dark theme for charts and the ability to run multiple instances of qStudio.
The changes were added as a few people had asked for a dark theme due to eye strain from staring at the white charts.
If you have any ideas for what you would like to see in the next version please let me know.
john AT timestored DOT com
Here’s a preview of a time series graph:
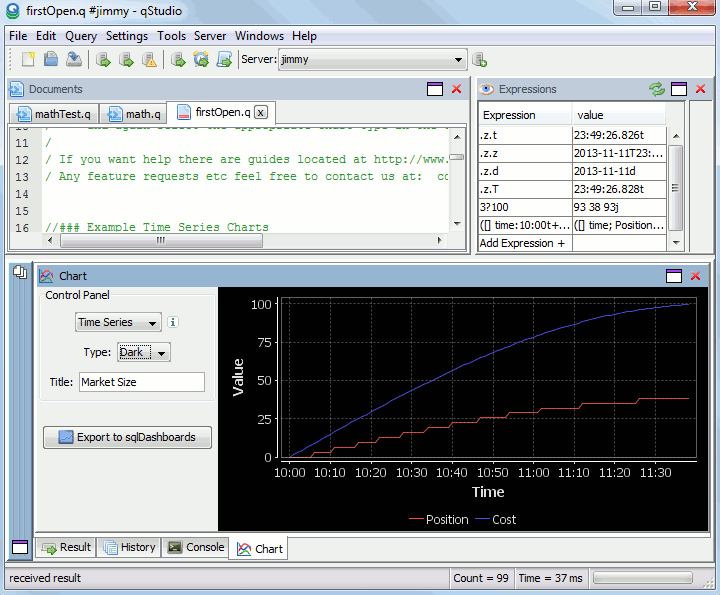
qStudio with a dark time series chart
October 28th, 2013 by John Dempster
Typical feed handlers for kdb+ are for market data and trade data such as bloomberg B-Pipe or reuters market feeds. These feeds typically contain ticker symbol, bid price, ask price and the time. We’ve been working on something a little different, a twitter feed handler. With this feed handler you can subscribe to:
- A random sample of all tweets
- Certain search queries
- Locations, tweets for any trending queries will be downloaded for those areas
For each tweet we have associated meta data that includes: location, language, time of posting and number of favourites/retweets.
Now that we have our data in kdb+ we can analyse it like any other time-series data and look for interesting patterns. If you have worked on anything similar I would love to hear about it (john AT timestored.com). I find treating social media data as time-series data throws up many interesting possibilities, in future blog posts I’ll start digging into the data..
At TimeStored we have previously implemented a number of market data feed handlers. Handling reconnections, failover, data backfilling and data enrichment can be a tricky problem to get right, if you need a feed handler developed we provide kdb+ development, consulting and support services, please contact us.
Basic examples of Java kdb+ Feed handlers and C Feed Handlers are available on the site.
July 8th, 2013 by Ryan Hamilton
qStudio is an editor for kdb+ database by kx systems. Version 1.28 of qStudio is now available for download:
http://www.timestored.com/qstudio/
Changes in the latest version include:
- Added Csv Loader (pro)
- Added qUnit unit testing (pro)
- Bugfix to database management column copying.
- Export selection/table bugs fixed and launches excel (thanks Jeremy / Ken)
The Kdb+ Csv Loader allows loading local files onto a remote kdb+ server easily from within a GUI.
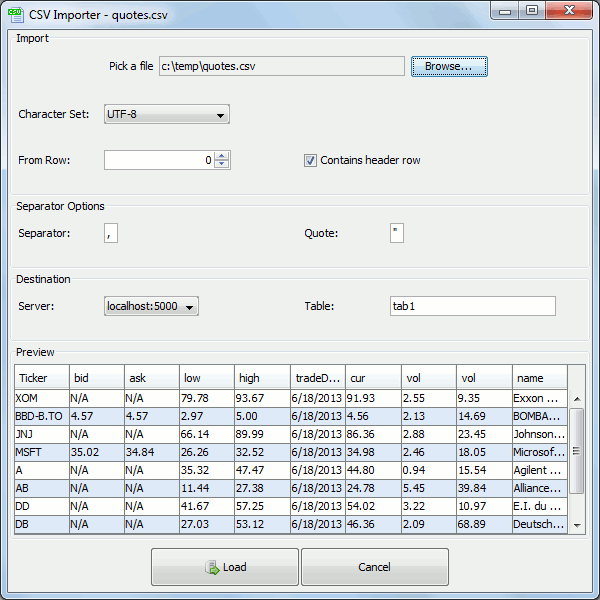
For step-by-step instructions see the qStudio loader help.
qUnit allows writing unit tests for q code in a format that will be familiar to all those who have used junit,cunit or a similar xunit based test framework. Tests depend on assertions and the results of a test run are shown as a table like so:
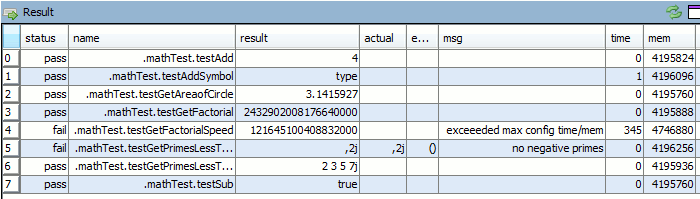
Tests are specified as functions that begin with the test** prefix and can have time or memory limits specified.
May 15th, 2013 by Ryan Hamilton
Sanket Agrawal just posted some very cool code to the k4 mailing list for finding the longest common sub-sequences. This actually solves a problem that some colleagues had where they wanted to combine two tickerplant feeds that never seemed to match up. Here’s an example:
q)/ assuming t is our perfect knowledge table
q)t
time sym size price
------------------------
09:00 A 8 7.343062
09:01 A 0 5.482385
09:02 B 5 8.847715
09:03 A 1 6.78881
09:04 B 5 3.432312
09:05 A 0 0.2801381
09:06 A 2 3.775222
09:07 B 3 1.676582
09:08 B 7 7.163578
09:09 B 4 3.300548
Let us now create two tables, u and v, neither of which contain all the data.
q)u:t except t 7 8
q)v:t except t 1 2 3 4
q)u
time sym size price
------------------------
09:00 A 8 7.343062
09:01 A 0 5.482385
09:02 B 5 8.847715
09:03 A 1 6.78881
09:04 B 5 3.432312
09:05 A 0 0.2801381
09:06 A 2 3.775222
09:09 B 4 3.300548
q)v
time sym size price
------------------------
09:00 A 8 7.343062
09:05 A 0 0.2801381
09:06 A 2 3.775222
09:07 B 3 1.676582
09:08 B 7 7.163578
09:09 B 4 3.300548
We can find the indices that differ using Sankets difftables function
q)p:diffTables[u;v;t `sym;`price`size]
q)show p 0; / rows in u that are not in v
1 2 3 4
q)show p 1; / rows in v that are not in u
3 4
/ combine together again
q)`time xasc (update src:`u from u),update src:`v from v p 1
time sym size price src
----------------------------
09:00 A 8 7.343062 u
09:01 A 0 5.482385 u
09:02 B 5 8.847715 u
09:03 A 1 6.78881 u
09:04 B 5 3.432312 u
09:05 A 0 0.2801381 u
09:06 A 2 3.775222 u
09:07 B 3 1.676582 v
09:08 B 7 7.163578 v
09:09 B 4 3.300548 u
q)t~`time xasc u,v p 1
1b
The code can be downloaded at:
http://code.kx.com/wsvn/code/contrib/sagrawal/lcs/miller.q
http://code.kx.com/wsvn/code/contrib/sagrawal/lcs/myers.q
Thanks Sanket.
Algorithm details:
Myers O(ND): http://www.xmailserver.org/diff2.pdf
Miller O(NP): http://www.bookoff.co.jp/files/ir_pr/6c/np_diff.pdf
April 2nd, 2013 by admin
The excellent Q For Mortals: A Tutorial In Q Programming by Jeffry Borror will soon be updated to version 3.
Jeff mentioned it at the recent NY user meeting.
You can read q for mortals online for free at: http://code.kx.com/wiki/JB:QforMortals2/contents
version 2 – added a new chapter on kdb database disk storage.
He said to get in touch if there’s anything you feel you would really like added.
UPDATE December 2015
q for mortals 3 is now out.
Q for Mortals Version 3 is a thorough presentation of the q programming language and an introduction to the kdb+ database. It is a complete rewrite of the original Q for Mortals that is current with q3.3. The presentation is derived from classes taught by the author at international financial institutions over the last decade. It is a series of tutorials based on q snippets intended to be entered interactively into the q console by the reader. The text takes its subject seriously but not itself. Technical explanations are augmented by mathematical observations, references to general programming concepts and other programming languages, and bad jokes. Coding style recommendations and advice to avoid gotchas appear liberally throughout. Examples are as simple as they can be but no simpler.
- Chapter 1, Q Shock and Awe, provides a piquant panorama of the power of q and its dazzling zen-like nature.
- Chapter 2 describes the base data types of q.
- Chapter 3 discusses lists, the fundamental data structure of q
- Chapter 4 presents the basic operators.
- Chapter 5 introduces dictionaries, which associate keys and values.
- Chapter 6 presents an in-depth description of functions and q’s constructs for functional programming.
- Chapter 7 demonstrates transforming data from one type to another.
- Chapter 8 introduces tables and keyed tables, the fundamental data structures for kdb.
- Chapter 9 describes q-sql and all the methods to manipulate tables.
- Chapter 10 presents ways to control execution of q programs.
- Chapter 11 covers file and interprocess communication I/O
- Chapter 12 describes workspace organization and management.
- Chapter 13 discusses system commands and command line parameters.
- Chapter 14 serves as an introduction to the kdb+ database. M
Available at all good bookstores.
http://www.amazon.com/For-Mortals-Version-Introduction-Programming/dp/0692573674
qTips is also good: http://www.amazon.co.uk/Tips-Fast-Scalable-Maintainable-Kdb/dp/9881389909
April 2nd, 2013 by admin
Added four new tutorials for those starting to learn kdb:
March 27th, 2013 by admin
q Code File Browser and Adding Multiple Kdb Servers
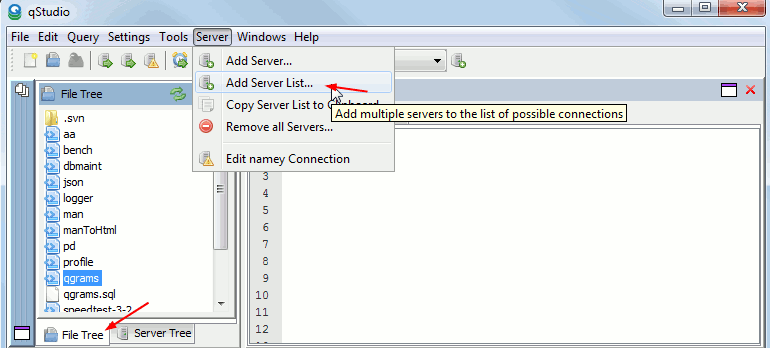
Added IDE Features:
- Add File Tree that allows browsing directory and providing autocomplete
- qDoc supports custom user tags (Thanks Aaron)
- Allow adding/exporting whole lists of servers at once (much quicker)
- Installers are now signed.
- Ctrl-D “goto definition” of function to open that file/position
- (PRO) Unit Testing and function profiling partially integrated.
March 27th, 2013 by admin
Added qStudio Features:
- Faster chart drawing (~1.6x faster)
- Added No Redraw chart option for those who want extra speed
- Numerous bugfixes to charts that froze
- Allow setting code editor font size
- Fix display of boolean/byte lists