
 PeachQ
PeachQ
MIT-licensed open source q. An early preview you can try in the browser.
Kdb has timeseries data specific joins that provide powerful tools for analysing tick data in particular. Due to kdb being column-oriented and based on ordered lists, the syntax is usually much more concise and the speed much faster than standard sql databases.
We will use the following simplified trade-t and quote-q tables to demonstrate the various joins.
Quote Table q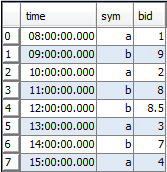 |
Trade Table t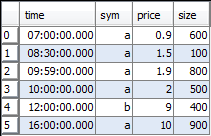 |
aj[ cols; sourceTable; lookupTable]aj0[ cols; sourceTable; lookupTable]For each row in the source table lookup a matching value in the lookup table, by matching on the columns specified in cols. cols is a list of column names where the initial columns MUST match exactly and the last column matches the closest value LESS-THAN in the source table.
AJ0 is the exact same as aj but returns the lookup tables time column.
Asof is a built-in kdb function, that provides a limited version of AJ, you may find it used occasionally.
An alternative method of viewing time-series data for examing sequential events between tables, is using the union join uj to get a combined table then sorting the full table on time.
Running time-series joins such as AJ on large amounts of data takes a significant amount of time. By applying a grouped attribute to the sym column we reduced the time from over half a second to under a tenth of a second. You must be careful running aj/wj's, particularly against on-disk data, it is recommended that you consult the documentation on code kx or consult an experienced kdb programmer if you have any issues.
We will use the following simplified trade-t and quote-q tables to demonstrate the various time window joins.
Quote Table q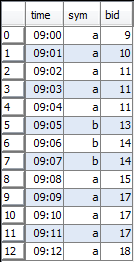 |
Trade Table t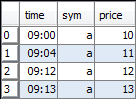 |
wj[ windows; cols; sourceTab; (lookupTab;(agg0;col0);(agg1;col1)]wj1[ windows; cols; sourceTab; (lookupTab;(agg0;col0);(agg1;col1)]For each row in the sourcetable, a time window pair is specified, matches on cols are then found and those that occur within the time window have the aggregate functions applied to the selected columns.
The only difference between wj1 and wj, the difference is that where wj pulls in
prevailing values not within the time window, wj1 strictly excludes values outside the interval.
MIT-licensed open source q. An early preview you can try in the browser.