Archive Page 4
April 2nd, 2018 by admin
qStudio has added support for stacked bar charts:
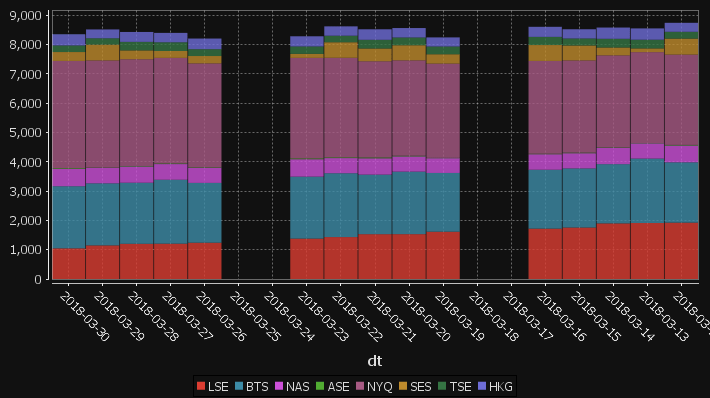
The chart format for this is: The first string columns are used as category labels. Whatever numeric columns appear next are a separate series in the chart. Each row in the data becomes one stacked bar. The table for the data shown above for example is:
| dt |
LSE |
BTS |
NAS |
ASE |
NYQ |
SES |
TSE |
HKG |
| 2018-03-30 |
1047 |
2120 |
592 |
25 |
3660 |
303 |
225 |
383 |
| 2018-03-29 |
1148 |
2118 |
528 |
10 |
3656 |
541 |
215 |
303 |
| 2018-03-28 |
1201 |
2085 |
555 |
17 |
3644 |
302 |
290 |
339 |
| 2018-03-27 |
1206 |
2182 |
535 |
21 |
3604 |
235 |
299 |
319 |
| 2018-03-26 |
1239 |
2041 |
515 |
16 |
3549 |
251 |
234 |
363 |
| 2018-03-25 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
| 2018-03-24 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
| 2018-03-23 |
1379 |
2115 |
595 |
29 |
3430 |
138 |
251 |
348 |
| 2018-03-22 |
1431 |
2179 |
517 |
25 |
3399 |
531 |
222 |
320 |
| 2018-03-21 |
1530 |
2032 |
558 |
29 |
3282 |
438 |
296 |
359 |
| 2018-03-20 |
1531 |
2134 |
520 |
23 |
3256 |
515 |
265 |
322 |
You may need to “kdb pivot” your original data to get it in the correct shape.
February 7th, 2017 by admin
This post is a walkthrough of my implementation in Q of the RosettaCode task ‘Death Star’.
The code is organized as general-purpose bitmap generator which can be used in other projects, and a client specific to the task of deathstar-drawing. The interface is a function which passes a map of pixel position to pixel value. The map can be a mapping function, or alternatively a 2D array of pixel values. The bitmap generator raster-scans the image, getting pixel values from either a mapping function or a mapped array.
genheader follows directly from the referenced BMP Wikipedia article.
genbitmap and genrow perform a raster scan of the image to be constructed. genbitmap steps along the vertical axis, calling genrow, which steps along the pixels of the current line, in turn calling fcn, the pixel-mapping function passed in by the client.
A sample client is included in comments, the simplest possible demonstration of shape and color (a circular mask selecting between two fill colors):
Conveniently, functions and arrays can be equivalently accessed in Q.
Here is an array-passing client which replicates the first example in the Wikipedia article on BMP format.
Element ordering can be confusing at first glance: Byte order for RGB pixels is B,G,R. Also, rows are indexed from bottom to top, and since bitmaps are in row-major order, the first and second array indices designated x and y correspond to the y and x image axes respectively.

After centering the image fcn applies several masks:
is calculates the orientation of a point on a sphere, and then a pixel value for that point, using the dot product of l, the light source direction, and s, the surface orientation. A correction of (1+value)/2 is applied, to achieve the ‘soft’ appearance of a space object in a movie. Alternatively we might have suppressed negative illumination values, to get the high-contrast appearance of an actual space object.
We might want to generate images of the death star at different rotations, however due to some simplifying assumptions we can’t rotate the weapon face to the side without glitching. We calculate z1 and z2 to select between the forward surface of the death star and the rearward surface of the weapon face. We should also calculate z3, the forward surface of the weapon face sphere, and z4, the rearward surface of the death star:
z3:170+z[x2;y;r];
z4:-z1;
Then the masks can be modified so that when z3 > z1 > z4 > z2, an additional bit of background is visible through the carved-out chunk of the deathstar.
TODO: discuss limitations of mask-and-fill; alternative approaches; display-list; …
TODO: discuss animation; …
TODO: discuss three-component architecture: orchestrator, world, bitmap generator
TODO: … conclusions
July 19th, 2016 by admin
I often get asked what open source alternatives are there to kdb+. The answer depends on what you are trying to do. IF there was a product XYZ that provided some similar features, whether it can replace kdb depends on a few issues:
>>”What will XYZ bring us that kdb doesn’t?”
Kdb has been tried and tested over many computer/man-years. The KX team have fixed 1000’s of edge cases, optimization issues and OS specific bugs. Any similar system would have to replicate a lot of that work. Possible but it would take time and teams actually using it. It would also require a corporate entity to provide support and bug fixes together with long term guarantees of availability (not a few part-time committers on github). Ontop of that it would need to deliver more value to make it worth switching.
Kdb is both a database and a programming language and it’s that combination which I believe gives kdb it’s unique power:
– There is no open source database that provides the speed kdb provides for the particular queries suited to finance.
– Combining kdb and basing queries on q-sql/ordered lists (rather than set theory for standard sql) means queries require fewer lines of code. I believe this expressiveness combined with longer term use of kdb/q changes how you think and allows easily forming queries which many people couldn’t begin to write in standard sql.
– However as much as I think q is a selling point of kdb, I know many others would disagree. It takes a reasonable period of time to convince someone non-standard SQL is beneficial.
What is your use case? e.g. Example Queries to Consider:
1. Select top N by category
http://stackoverflow.com/questions/176964/select-top-10-records-for-each-category
select n#price by sym from trade
2. Joining Records on nearest date time:
http://www.bigresource.com/MS_SQL-joining-records-by-nearest-datetime-XsKMeH3t.html
aj[`sym`time;select .. from trade where ..;select .. from quote]
3. Queries dependent on order. (eg price change, subtract row from previous)
http://stackoverflow.com/questions/919136/subtracting-one-row-of-data-from-another-in-sql
select price-prev price from trade....
XYZ would need to support these queries well. Why would I chose XYZ instead of Python/R/J/A+?
Existing (some similar languages) that offer a larger existing user base, more libraries and a proven/stable platform. Unless a way is found to leverage existing languages/libraries XYZ will be competiting for attention against kdb and also python/numpy/julia etc.
>>”bring in the cost factor and should XYZ be considered as a big future player?”
For the target market of kdb the cost is often not the most significant factor in the decision. If kdb can answer questions that other platforms can’t or in a much shorter time, it often adds enough value to make the cost irrelevant. In fact many large firms are happy paying a pricey support agreement for free open source software so that they have someone to (blame) call to resolve an issue quickly.
>>”but could XYZ catch up and begin to be trusted by bigger institutions?”
If XYZ started to be able to answer the three example queries shown above at a reasonable speed multiple perhaps but I consider it unlikely. Kdb is entrenched and for its target use case it is currently unbeatable. Some people may have use cases that don’t need the full power of database and language combined or have other important factors (cost,existing expertise). I think those use cases have viable open source solutions.
February 24th, 2016 by admin
First, in case you haven’t heard about it kdb has a standard SQL mode, you can send queries prefixed with s) and they will be interpreted as standard SQL like so:
Notice how the standard “and” syntax worked when I used s) but without it, q’s right to left evaluation causes problems. It’s about now that a lot of people get very excited, they think great I can skip learning that q-sql and use my standard SQL. Sometimes the look of joy on their faces transforms to frustration once they start using it. So let’s look at what works:
| Operation |
Works? |
| Standard SQL Inserts |
Yes |
| ORDER BY |
half works |
| COUNT |
Yes |
| DELETE |
Yes |
| UPDATE |
Yes |
| String matching |
slightly works |
| NOT |
NO |
| IN |
Yes |
| GROUP BY |
Yes |
| LIMIT / TOP |
NO |
| Date Times |
NO |
Standard SQL Inserts work
ORDER BY half works
“ORDER BY” will sort the columns in ascending order, attempting to use DESC has no effect.
COUNT works
DELETE works
UPDATE works
String matching slightly works
NOT fails
Modifying our String query slightly by adding NOT throws an error. My guess is that the interpreter has got confused.
IN works
GROUP BY works
LIMIT / TOP does not work
Date Times Don’t Work Right
Overall standard SQL support in kdb has got much better. However I would still recommend only using the s) syntax for plugging into an existing jdbc/odbc visualization tool and getting some immediate simple results. For any form of complex queries on strings, joins etc. support is either not there or the result may not be what you expect.
February 15th, 2016 by admin
qStudio 1.40 is now available to download.
The latest changes include:
- No need to save changes before shutdown, unsaved changes stored till reopened.
- Add sqlchart to system path.
- Fix display of tables with underscore in the name.
- Database documenter/report enhancements
- Improved code printing
- FileTreePanel much more efficient at displaying large number of files.
May 2nd, 2015 by admin
An intellij keyword file is now available to provide syntax highlighting of kdb code in intellij:
q Code Intellij Highlighting
To install it copy this xml file to this directory:
C:\Users\USERNAME\.IdeaIC14\config\filetypes
Where USERNAME is obviously your username. Then restart intellij and open a .q file.
We’ve updated our notepad++ qlang.xml to provide code folding and highlighting of the .Q/.z namespaces.
May 2nd, 2015 by admin
We’ve now posted all source code from this website on our github kdb page.
Additionally we are open sourcing qunit, our kdb testing framework.
We look forward to receiving pull requests to fix our (hopefully few) bugs.
April 23rd, 2015 by admin
Since our last qStudio kdb+ IDE announcment we have added a lot of new features:
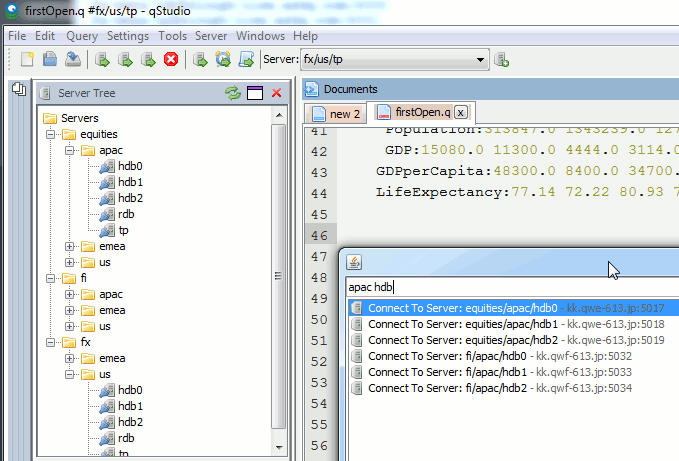
Bulk importing kdb server lists
There’s a lot of new features to allow supporting a huge number of servers efficiently:
- Support importing HUGE number of servers:
- 5000+ server connections are now supported
- To prevent massive memory use, the object tree for a server is no longer refreshed at startup only on connection.
- Allow specifying default username/password once for all servers
- Allow nested connection folders
- Add critical color option – servers with prod in name get highlighted in red
- Sort File Tree Alphabetically
- Numerous bugfixes including:
- Fix critical Mac bug that prevented launching in some instances
- Fix query cancelling
October 20th, 2014 by admin
Based on user requests we have released a number of new features with qStudio 1.36:
Download the latest ->qStudio<- now.
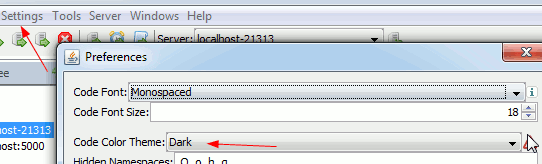
Dark Code Editor Themes
Which can be set under settings->preferences
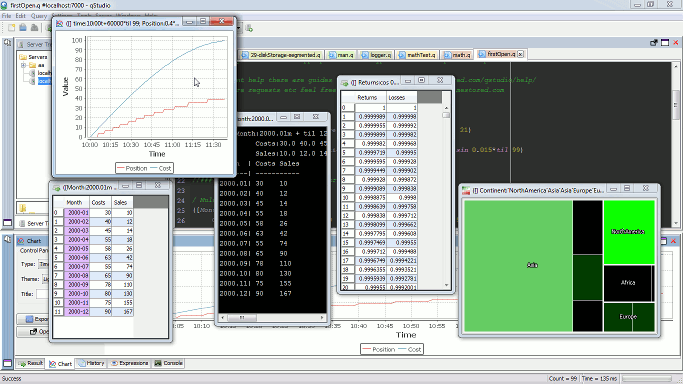
Open Results and Charts in New Window
To expand a panel into a new window click the “pop-out” icon.

This will bring up the result in a new window:
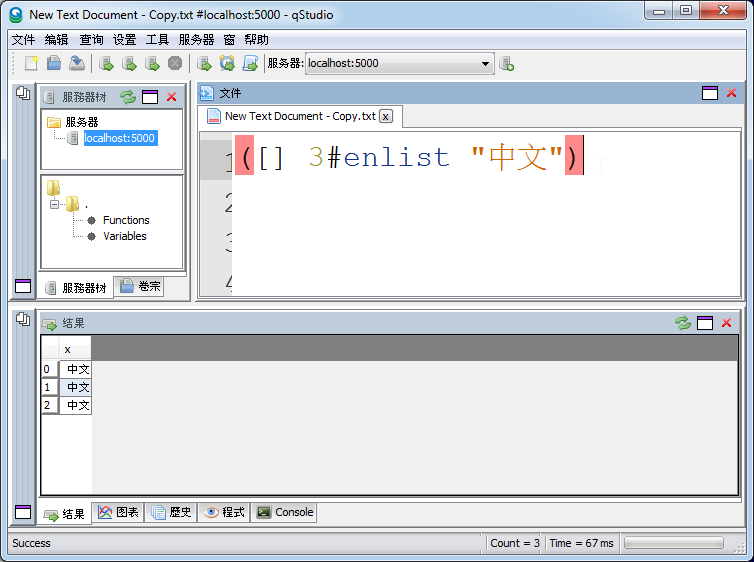
UTF-8 Chinese Language Support
October 20th, 2014 by admin
Newry-based financial software firm First Derivatives has acquired a majority shareholding in big data analytics company Kx Systems for £36m (€44m).
KX has historically had a hard time penetrating markets outside finance, FD have a good sales team and previously acquired a marketing company in Philadelphia, hopefully this is the chance for kdb+ to go mainstream.
However it’s a worry that FD (First Derivatives) may increasingly “encourage” purchasing of the delta platform bundle rather than stand-alone kdb+. With the smaller margins outside of finance, will FD take a risk and open up the database. (Would FD have been a supporter of the 32-bit version becoming free for commercial use?) There’s a large number of individuals in off-shore locations that want to learn kdb+, FD could be incentivized to discourage that as it would hurt their consulting business.
It’s also interesting to consider companies that have already invested in KX technology and whether they will continue to do so
- Competing consulting firms that specialise in kdb+ won’t take this as good news.
- Panopticon/Datawatch based their visualization system on kdb+ (OEM license), they probably regret that now, given that their visualization software directly competes with FD’s dashboards.
- Companies that had used kdb+ as part of their trading platform stack may consider FD a competitor as they also offer a trading platform.
What do you think? Will this lead to wider adoption? a growing platform?