Archive Page 4
April 13th, 2017 by Ryan Hamilton
kdb+ 3.5 had a significant number of changes:
- Debugger – At long last we can finally get stack traces when errors occur.
- Concurrent Memory Allocator – Supposedly better performance when returning large results from peach
- Port Reuse – Allow multiple processes to listen on same port. Assuming Linux Support
- Improved Performance – of Sorting and Searching
- Additional ujf function – Similar to uj from v2.x fills from left hand side
kdb Debugger
The feature that most interests us right now is the Debugging functionality. If you are not familiar with how basic errors, exceptions and stack movement is handled in kdb see our first article on kdb debugging here. In this short post we will only look at the new stack trace functionality.
Now when you run a function that causes an error at the terminal you will get the stack trace. Here’s a simple example where the function f fails:
Whatever depth the error occurs at we get the full depth stack trace, showing every function that was called to get there using .Q.bt[]:
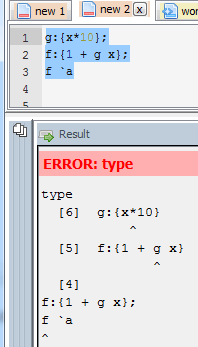
The good news is that this same functionality is availabe in qStudio 1.43. Give it a try: qStudio.
Note: the ability to show stack traces relies on qStudio wrapping every query you send to the server with its own code to perform some analysis and return those values. By default wrapping is on as seen in preferences. If you are accessing a kdb server ran by someone else you may have to turn wrapping off as that server may limit which queries are allowed. Unfortunately stack tracing those queries won’t be easily possible.
That’s just the basics, there are other new exposed functions and variables, such as .Q.trp – for trapping calls and accessing traces that we are going to look at in more detail in future.
February 27th, 2017 by Ryan Hamilton
qUnit has added a new HTML report to allow visually easily seeing the difference between expected kdb results and actual results. To generate a report you could call:
.qunit.generateReport[.qunit.runTests[]; `:html/qunit.html]
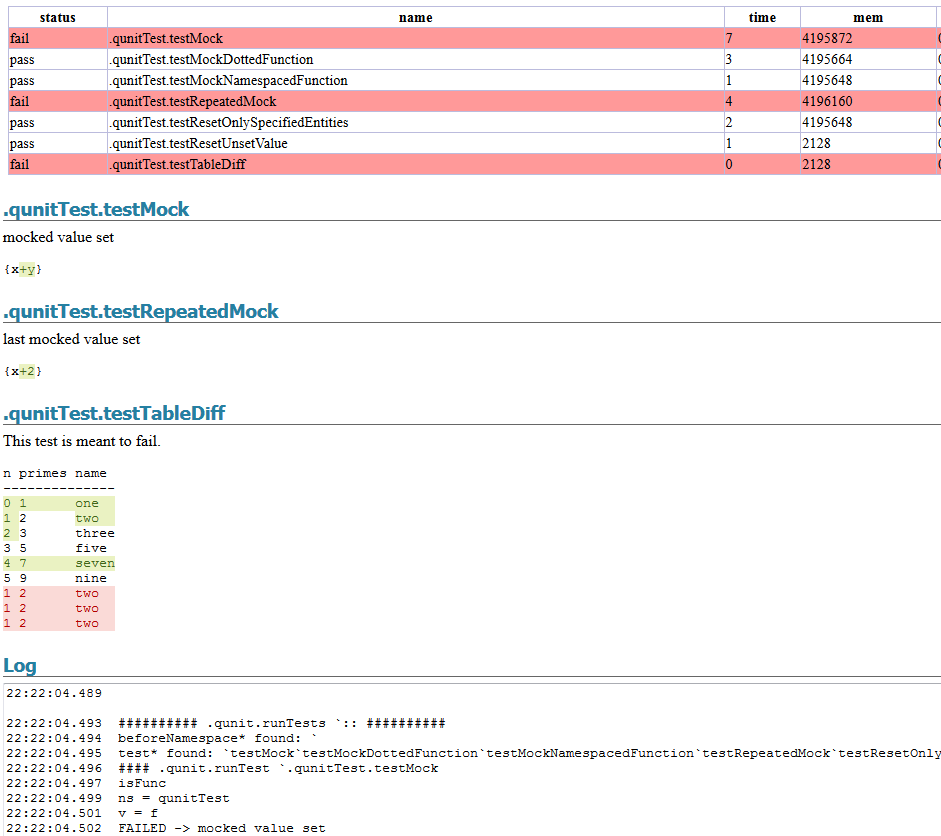
It’s also added a
.qunit.assertKnown[actualResult; expectedFilename; msg]
call to allow comparing an actual results to a file on disk. While allow easy updating of that file and avoiding naming collisions.
February 7th, 2017 by Ryan Hamilton
Download the latest qStudio now.
qStudio Improvements
- Bugfix Sending empty query would cause qStudio to get into bad state.
- Default to chart NoRedraw when first loaded to save memory/time.
- Preferences Improvements
- Option to allow saving Document with windows \r\n or linux \n line endings. Settings -> Preferences… -> Misc
- Allow specifying regex for folders that should be ignored by the “File Tree” window and Autocomplete
- Add copy “hopen `:currentServer” command button to toolbar.
- Ctrl+p Shortcut – Allow opening folders in explorer aswell as files.
- Smarter Background Documents Saving (30 seconds between saves on background thread)
sqlDashboards Improvements
- Allow saving .das without username/password to allow sharing. Prompt user on file open if cant connect to server.
- Bugfix: Allow resizing of windows within sqlDashboards even when “No table returned” or query contains error.
- If query is wrong and missing arg or something, report the reason.
- Stop wrapping JDBC queries as we dont want kdb to use the standard SQL handler. We want to use the q) handler.
June 25th, 2016 by Ryan Hamilton
qStudio 1.41 is now available to download.
It adds the ability to use custom Security Authentications and custom JDBC drivers.
By automatically loading .jar plugins from libs folder.
After a few users reported issues around “watched expressions” we are removing the ctrl+w shortcut as it was often getting used by mistake. The last change was some internal work to improved startup/shutdown logging for debugging purposes..
April 26th, 2016 by Ryan Hamilton

Recently there was a post on SQL tips by the JOOQ guys. I love their work but I think standard SQL is not the solution to many of these problems. What we need is something new or in this case old, that is built for such queries. What do I mean, well let’s look through their examples reimplemented in qsql and I’ll show you how much shorter and simpler this could be.
Everything is a table
In kdb we take this a step further and make tables standard variables, no special notation/treatment, it’s a variable like any other variable in your programming language. Instead of messing about with value()() we define a concise notation to define our variables like so:
Data Generation with Recursive SQL
This is the example syntax they have used to define two tables and then join them:
What to hell! If I want variables, let’s have proper variables NOT “Common Table Expressions”.
I created two tables a and b then I joined them sideways. See how simple that was.
Running Total Calculations
Oh dear SQL how badly you have chosen your examples. Running calculations are to APL/qSQL as singing is to Tom Jones, we do it everyday all day and we like it. In fact the example doesn’t even give the full code. See this SO post for how these things get implemented. e.g. Standard SQL Running Sum
qSQL table Definition and Running Sum:
Finding the Length of a Series
This is their code:
This is KDB:
In 1974 Ken Iverson gave a talk on APL. He described how he reduced it down to a core set of operations that everything could be made from. Using these simple building blocks you could make some really cool things. It’s sad to think we may not have came that far.
qSQL/kdb is a database based on the concept of ordered lists, carrying over many ideas from APL that make array operations shorter and simpler. If you like what you see we provide tutorials on kdb to get started, this intro is a good place to get started.
We also have free online kdb training for students.
November 16th, 2015 by Ryan Hamilton
Julia programming language is being touted as the next big thing in scientific programming. It’s high-level like R/Python but meant to be much faster due to its smart compiler. I’ve been giving it a bit of a tryout, as part of learning it I’ve generated a list of all julia functions and will be creating examples for some of the more popular ones.
July 1st, 2015 by Ryan Hamilton
Free kdb+ Twitter Feedhandler

Previously we showed a demo of us getting data from twitter into kdb, we are now open sourcing part of that work, allowing you to quickly get some real social data into kdb to play with.
If you want to try running the kdb twitter data feed visit our https://github.com/timeseries and see the twitter-kdb project. You can even download the jar straight from our releases page. Here’s an image of the command line version running:
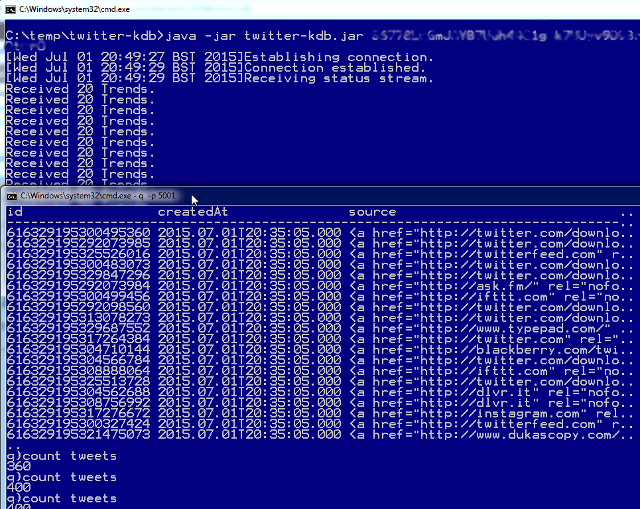
You will need to setup API keys for twitter
April 20th, 2015 by Ryan Hamilton
Benchmarking Smart Meter Data Analytics – I got forwarded this interesting paper that compares how quickly smart meter data can be analysed using
- a Relational Database
- Matlab
- An in-memory Column-Oriented database
- Two new NoSQL alternatives
Smart electricity grids, which incorporate renewable energysources such as solar and wind, and allow information sharingamong producers and consumers, are beginning to replace conventional power grids worldwide. Smart electricity meters are afundamental component of the smart grid, enabling automated collection of fine-grained (usually every 15 minutes or hourly) consumption data. This enables dynamic electricity pricing strategies,in which consumers are charged higher prices during peak timesto help reduce peak demand. Additionally, smart meter data analytics, which aims to help utilities and consumers understand electricity consumption patterns, has become an active area in researchand industry. According to a recent report, utility data analytics isalready a billion dollar market and is expected to grow to nearly 4billion dollars by year 2020
January 19th, 2015 by Ryan Hamilton
In a world overran with open source big data solutions is kdb+ going to be left behind? I hope not…
Every few weeks someone comes to me with a big data problem often with a half-done mongoDB/NoSQL solution that they “want a little help with”. Usually after looking at it I think to myself
“I could solve this in 20 minutes with 5 lines of q code”
But how do I tell someone they should use a system which may end up costing them £1,000s per core in licensing costs. Yes it’s great that there’s a free 32-bit trial version but the risk that you may end up needing the 64-bit is too great a risk.
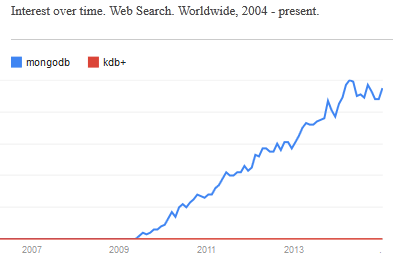
Given the ever-increasing number of NoSQL solutions and in particular the rising popularity of Hadoop, R, python and MongoDB it’s not hard to see that open-source is taking over the world. Right now kdb+ still has the edge, that it’s faster, sleeker, sexier..but I don’t think that will save it in the long run. The power of open-source is that it let’s everyone contribute, witness the 100’s of libraries available for R, the 1000’s of javascript frameworks. The truly sad thing is that it’s not always the best underlying technology that wins. A 1000 amateurs creating a vibrant ecosystem of plug-ins, add-ons, tutorials… can beat other technologies through sheer force of numbers.
- APL was a great language yet it remains relegated to history while PHP flourishes.
- PostgreSQL was technically superior to MySQL yet MySQL is deployed everywhere
I believe kdb+ is the best solution to a large number of “big data” problems (small data to kdb+), When you stop and think, time-series data is everywhere, open sourcing kdb+ would open up entirely new sectors to kdb+ and I hope it’s a step kx take before it’s too late.
What do you think? Leave your comments below.
March 30th, 2014 by Ryan Hamilton
Often at the start of one of our training courses I’m asked why banks use the Kdb Database for their tick data.
- One well known reason is that kdb is really fast at typical financial time-series queries
(due to Kdbs column-oriented architecture).
- Another reason is that qSQL is extremely expressive and well suited for time-series queries.
To demonstrate this I’d like to look at three example queries, comparing qSQL to standard SQL.
SQL Queries dependent on order
From the table below we would like to find the price change between consecutive rows.
| time |
price |
| 07:00 |
0.9 |
| 08:30 |
1.5 |
| 09:59 |
1.9 |
| 10:00 |
2 |
| 12:00 |
9 |
|
|
q Code
In kdb qSQL this would be the extremely simple and readable code:
Standard SQL
In standard SQL there are a few methods, we can use. The simplest is if we already have a sequential id column present:
Even for this simple query our code is much longer and not as clear to read. If we hadn’t had the id column we would have needed much more code to create a temporary table with row numbers. As our queries get more complex the situation gets worse.
Select top N by category
Given a table of stock trade prices at various times today, find the top two trade prices for each ticker.
trade table
| time |
sym |
price |
| 09:00 |
a |
80 |
| 09:03 |
b |
10 |
| 09:05 |
c |
30 |
| 09:10 |
a |
85 |
| 09:20 |
a |
75 |
| 09:30 |
b |
13 |
| 09:40 |
b |
14 |
|
|
qSQL Code
In q code this would be select 2 sublist desc price by sym from trade, anyone that has used kdb for a few days could write the query and it almost reads like english. Select the prices in descending order by sym and from those lists take the first 2 items (sublist).
SQL Code
In standard SQL a query that depends on order is much more difficult , witness the numerous online posts with people having problems: stackoverflow top 10 by category, mysql first n rows by group, MS-SQL top N by group. The nicest solution, if your database supports it, is:
The SQL version is much harder to read and will require someone with more experience to be able to write it.
Joining Records on Nearest Time
Lastly we want to consider performing a time based join. A common finance query is to find the prevailing quote for a given set of trades. i.e. Given the following trade table t and quote table q shown below, we want to find the prevailing quote before or at the exact time of each trade.
trades t
| time |
sym |
price |
size |
| 07:00 |
a |
0.9 |
100 |
| 08:30 |
a |
1.5 |
700 |
| 09:59 |
a |
1.9 |
200 |
| 10:00 |
a |
2 |
400 |
| 12:00 |
b |
9 |
500 |
| 16:00 |
a |
10 |
800 |
|
quotes q
| time |
sym |
bid |
| 08:00 |
a |
1 |
| 09:00 |
b |
9 |
| 10:00 |
a |
2 |
| 11:00 |
b |
8 |
| 12:00 |
b |
8.5 |
| 13:00 |
a |
3 |
| 14:00 |
b |
7 |
| 15:00 |
a |
4 |
|
|
In qSQL this is: aj[`sym`time; t; q], which means perform an asof-join on t, looking up the nearest match from table q based on the sym and time column.
In standard SQL, again you’ll have difficulty: sql nearest date, sql closest date even just the closest lesser date isn’t elegant. One solution would be:
It’s worth pointing out this is one of the queries that is typically extremely slow (minutes) on row-oriented databases compared to column-oriented databases (at most a few seconds).
qSQL vs SQL
Looking at the simplicity of the qSQL code compared to the standard SQL code we can see how basing our database on ordered lists rather than set theory is much more suited to time-series data analysis. By being built from the ground up for ordered data and by providing special time-series based joins, kdb let’s us form these example queries using very simple expressions. Once we need to create more complex queries and nested selects, attempting to use standard SQL can quickly spiral into a verbose unmaintainable mess.
I won’t say qSQL can’t be cryptic 🙂 but for time-series queries qSQL will mostly be shorter and simpler than trying to use standard SQL.
If you think you have shorter SQL code that solves one of these examples or you are interested in one of our kdb training courses please get in touch.