Archive Page 2
September 25th, 2023 by Ryan Hamilton
If you work with data, at some point you will be presented with a powerpoint similar to this:

A wonderful fictional land, where we cleanly build everything on the layer below until we reach the heavens (In the past this was wisdom or visualization, increasingly it’s mythical AI).
There are two essential things missing from this:
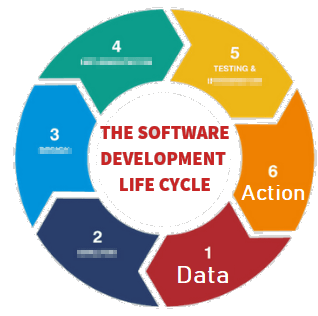
- At the end of every data sequence, should be an Action.
If there isn’t, what are we even attempting to do?
Wisdom – should lead to action. A visualization or email alert should prompt Action. But there MUST always be action.
- At every stage, there is feedback. It’s a cycle not a mythical pyramid or promised land.
I’ve never met anyone working with data, that didn’t find something out at a later stage that meant having to go back and rework their previous steps.
e.g.
- Looking at the average height of males, The United States shows 5.5m, oops I guess I better go back and interpret that as feet instead of metres.
- Based on analysis, you tried emailing a subset of customers that should have converted to paying customers at 5% rate, but they didn’t. So based on action, you discovered you were wrong. Time to go back to the start and examine why.
Therefore the diagram should look more like this:
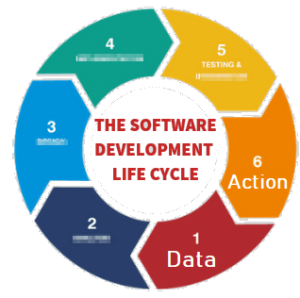
You start with data, you reach Action but at any stage, including after action you can loop back to earlier stages in the cycle.
I’ve purposely blurred out the steps because it doesn’t matter what’s inbetween. Inbetween should be whatever gets your team to the action quickest with the acceptable level of risk. Notice this is the SDLC software development lifecycle. Software people spent years learning this lesson and it’s still an ongoing effort to make it a proper science.
What do you think? Am I wrong?
August 15th, 2023 by Ryan Hamilton
Our latest product Pulse is for displaying real-time interactive data direct from any database. To get most benefit, the underlying databases need to be fast (<200ms queries). For our purposes databases fall into 2 categories:
- Really really fast, can handle queries every 200ms or less and seamlessly show data scrolling in
- All Other Databases. The 95%+.
It’s very exciting when we find a new database that meets that speed requirement. I went to the website, downloaded QuestDB and ran it. Coming from kdb+ imagine my excitement at seeing this UI:
Good News:
- A very tiny download (7MB .jar file)
- There’s a free open source version
- They are focussed on time-series queries
- Did I mention it’s fast
I wanted to take it for a spin and to test the full ingestion->store->query cycle. So I decided to prototype a crypto dashboard. Consume data from various exchanges and produce a dashboard of latest prices, trades and a nice bid/ask graph as shown below.
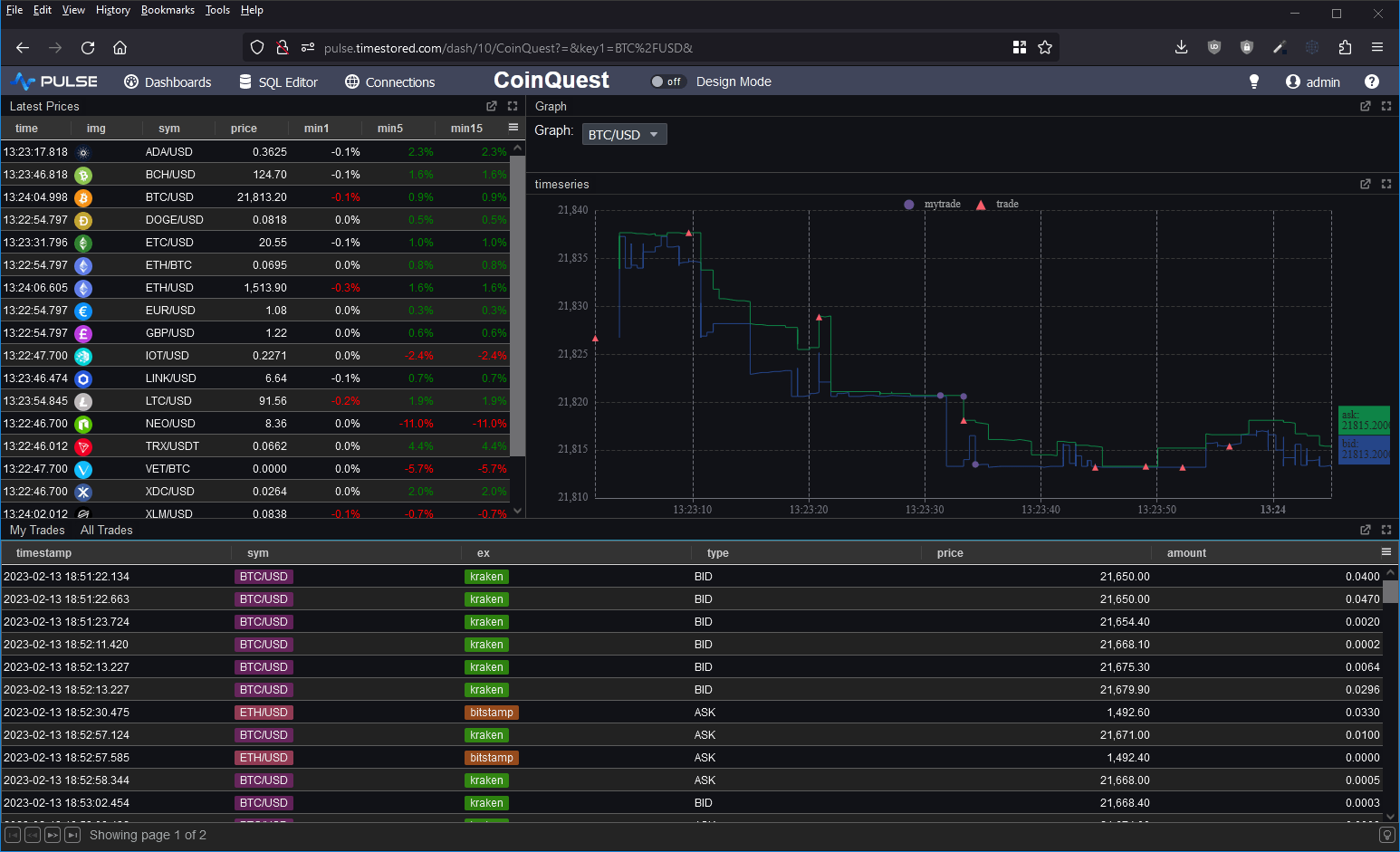
Good Points
- It simply worked.
- QuestDB chose to be PostgreSQL wire and query compatible. A great technical choice as:
- It will work with many tools including Pulse without complication
- Many people already know SQL. I’ve been teaching q/kdb for years and when people learn it, you can use it for absolutely amazing things that standard SQL is terrible at. However most people do not reach that level of expertise. By using standard SQL more people can reuse their existing knowledge.
- They then added Time-series specific extensions ontop for querying, including:
- “Latest on” – that’s equivalent to kdbs “last by”. It’s used to generate the “latest prices” table in the dashboard with a 1/5/15 minute lag.
- ASOF Joins
- QuestDB can automatically create tables when you first send data, there’s no need to send “Create Table …”. This was useful when I was tweaking the data layout from the crypto feeds.
- At parts my SQL was rusty and I asked for help on their slack channel. Within an hour I got helpful responses to both questions.
Within a very short time, I managed to get the database populated and the dashboard live running. This is the first in a long time that a database has gotten me excited. It seems these guys are trying to solve the same user problems and ideas that I’ve seen everywhere. There were however some significant feature gaps.
Feature Gaps
- No nested arrays. If I want to store bid/asks, I can only currently do it with columns bid1/bid2/bid3, no arbitrary length arrays.
- Very limited window analytics. Other than “LATEST ON” QuestDB won’t let me perform analysis within that time window or within arrays in general.
- I really missed my
`time xasc (uj/)(table1;table2)
pattern for combining multiple tables into one. For the graph I had to use a lengthy SQL UNION.
In general kdb+ has array types and amazingly lets you use all the same functions that work on columns on nested structures. I missed that power.
- No security on connections. It seems security integration will be an enterprise feature.
Open Source Alternative to kdb+ ?
Overall I would say not yet but they seem to be aiming at a similar market and they are moving fast.
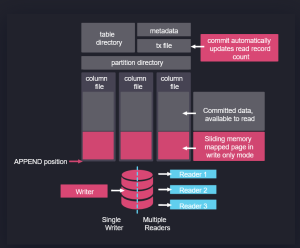
In fact, if you look at their architecture on the right, it’s obvious some of their team have used kdb+. Data is partitioned on date, with a separate folder per table and a column per file. Data is mapped in when read and appended when new data arrives.
In some ways this architecture predates kdb+ and originates from APL. It’s good to see new entrants like QuestDB and apache arrow pick up these ideas, make them their own and take them to new heights. I think kdb+ and q are excellent, I was always frustrated that it has remained niche while inferior technical solutions became massively popular, if QuestDB can take time-series databases and good technical ideas to new audiences, I wish them the best of luck!
Please leave any of your thoughts or comments below as I would love to hear what others think.
If you want to see how to setup QuestDB and a crypto dashboard yourself, we have a video tutorial:

August 15th, 2023 by Ryan Hamilton
Support for 30+ databases has now been added to both qStudio and Pulse.
Clickhouse, Redis, MongoDB, Timescale, DuckDB, TDEngine and the full list shown below are all now supported.
// Supports Every Popular Database
Pulse is being used successfully to deliver data apps including TCA, algo controls, trade blotters and various other financial analytics. Our users wanted to see all of their data in one place without the cost of duplication. Today we released support for 30+ databases.
“My market data travels over ZeroMQ, is cached in Reddit and stored into QuestDB. While static security data is in SQL server. With this change to Pulse I can view all my data easily in one place.” – Mark – Platform Lead at Crypto Algo Trading Firm.
// Highlighted Partners
In particular we have worked closely with chosen vendors to ensure compatibility.
A number of vendors have tested the system and documented setup on their own websites:
- TDEngine – Open-source time series database purpose-built for the IoT (Internet of Things).
- QuestDB – Open source time-series database with a similar architecture to kdb+ that supports last-by and asof joins. See our crypto Pulse demo.
- TimeScale – PostgreSQL++ for time series and events, engineered for speed.
- ClickHouse and DuckDB – Were tested by members of their community and a number of improvements made.
// The Big Picture

Download Pulse 1.36
Download qStudio 2.52
May 22nd, 2023 by Ryan Hamilton
I won’t go through the full list of great presentations as Gary Davies has that excellently covered but I will highlight some trends I saw at kxcon 2023:
- APIs are powerful abstractions that users need and love –
- Erin Stanton (Virtu) – Brought massive amounts of energy to her presentation, showing how accessing powerful “getData” APIs from python->kdb allowed Erin to run machine learning models in minutes rather than hours. As a python enthusiast she was very happy to use the power of kdb without having to know it well. Erin demonstrated an easily browsable web interface that allowed data discovery, provided documentation and could be used to run live data queries.
- Alex (TD) – Similarly discussed how his team all used python wrapped APIs to allow sharing smart query defaults such as ignoring weekend data to prevent less sophisticated users from shooting themselves in the foot.
- Igor (Pimco) – Mentioned the power of APIs and how hiding the tables allowed changing implementations later.
- Python is super popular
- Citadel, Alex (TD), Erin (Virtu), Nick Psaris, Rebecca (Inqdata) all included significant python demonstrations.
- Citadel – Has built an improved Python/Pykx process that uses a proxy thread to subscribe and publish updates extremely fast. They are using this as part of a framework to allow quants to publish data and construct DAGs (directed acyclic graphs) of calculations to produce analytics.
Why users love APIs and Python?
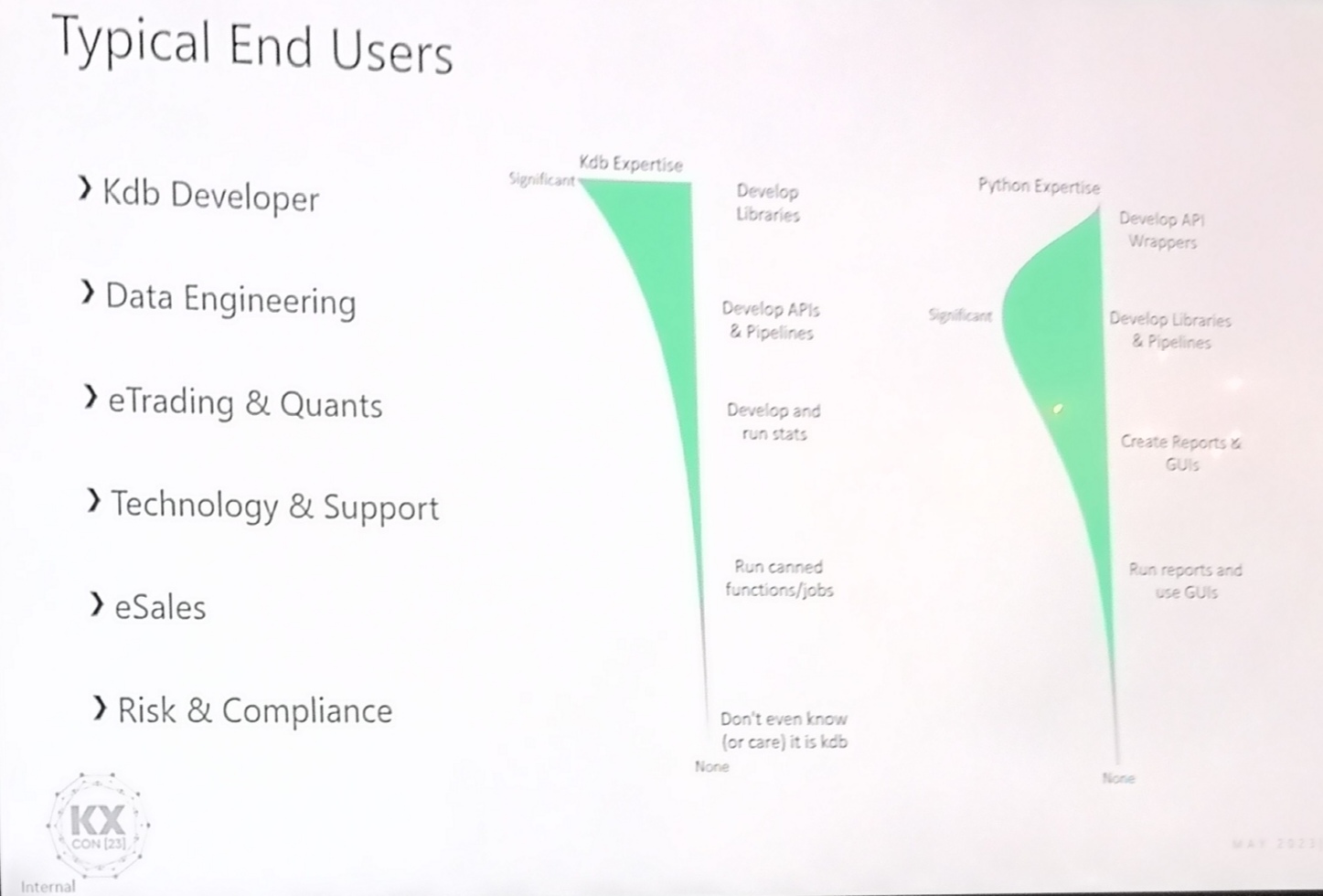
Alex Donohue’s presentation was packed with years of condensed knowledge , including the excellent diagram below showing typical user expertise. Notice as it transitions from backend kdb developers to frontend business users:
- The level of kdb expertise drops off quickly (non-linear)
- The data engineers and quants know much more python than kdb
- I would like to add one more graph, showing business / domain knowledge.
That graph would be low for many kdb developers but higher for sales and trading.
Looking at it this way, makes it clear we need to provide APIs as users want to express queries in their own language.

Other Patterns at kx Con:
- Small Teams can really deliver with kdb – Numerous times we heard how a small team used kdb to deploy a full solution quicker, that scaled better and ran faster than all alternatives.
- But costly per CPU licensing can be restricting to those teams.
- ChatGPT is everywhere – Rebeccas QuBot chatbot and Aaron Davies presentations demoed GPTs.
May 22nd, 2023 by Ryan Hamilton
- kdb now on AWS – kdb as a fully managed service under finspace – The website says available in June but at least one big investment bank is trialling it and having talked to a representative at AWS a significant amount of work and effort has gone into this. This is great to see. I think for the future of KX this needs to work. It doesn’t make sense for every firm to reinvent the wheel, banks could afford to do it but smaller firms cannot.
- kdb.ai – seems to be repositioning kdb as a vector database for AI – currently it’s a few blog posts, whether there’s a real product or it’s to ride the AI hype train we will have to wait and see. Given the hype other inferior databases have received in the past, kdb deserves some attention.
- Run q code on Snowflake – Snowflake is a column oriented database that only runs in the cloud and uses a central storage with compute nodes to service SQL queries. They provide snowpark that allows running java, python and now q close to the data. I’m unsure who the target of this is, many users struggle to fully understand one database without inception.
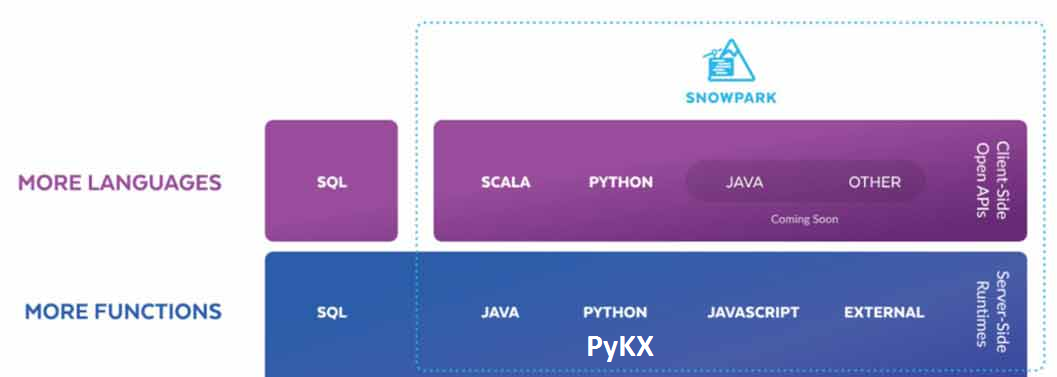
Additionally kx:
- announced PyKX will be open source?? (exact details to be confirmed, as repo is not available today 2023-05-21)
- PyKX may add the ability to act as a very fast event processor
- Announced improved vs code support will arrive shortly
- The Core team demoed some really cool functionality, I’m not sure it was all meant to be public so I will just say some parts were similar to Destructuring Assignment in javascript.
April 28th, 2023 by Ryan Hamilton
Are you a Quant or kdb Developer struggling to get the UI team to work on your app?
With Pulse, you can now build interactive data tools fast by yourself.
Pulse version 1.0 is available to download now and allows you to build real-time interactive data apps, free for up to 3 users.
After an intense year working closely with groups of quants and data analysts, with releases every week, Pulse has reached a major milestone.
Pulse 1.0 is being used successfully to deliver data apps including:
- TCA – Transaction Cost Analysis
- Algo start/stop and limit controls
- Trade Blotters that update in real-time
- Live Price Charts
Find Out More
Pulse now provides:
A massive thanks to the many beta testers, early adopters, users and companies that invested in and purchased Pulse.
Particular thanks to Rahul, Ruairi, Ian, Steve, Chris, WooiKent, Franco, Palmit, JP, JD, PN, SG, JM, KF, AR, MC, JC, CA, SS. Thanks for raising numerous feature requests and providing excellent feedback that helped make Pulse what it is today.
If you want to hear more, join one of our scheduled demos or contact us.
If you tried an old version or if you have never tried Pulse:
Download Pulse Now
March 14th, 2023 by Ryan Hamilton
0.6.5 release in July 2022
For our initial release of Pulse we had 4 essential use cases that we solved. This included:
- Trade Blotter – Scrolling real-time table of trades.
- TAQ – Trade and Quote graph of teal-time quotes
- A live updating current price table with color highlighting.
- A simple time-series graph to plot single metrics. e.g. mid price over time.
1.0 Release March 2023
Pulse is a tool for real-time interactive dashboards.
Over the last few months we focussed on adding new visualizations , allowing charts/tables to be customized and supporting QuestDB.
The goal for 1.0 is:
- Increased Interactivity – To allow user interaction
- Support for large deployments
- Dynamically updating data sources – For when db server deployments can change host/port
- Licensing – builtin
- Reporting tools – to show current and historical dashboard usage
- Possible custom connection to user to allow security.
- Stability
- Warn when dashboard is growing very large
- websocket heartbeat to prevent idle disconnects
- Improved User Friendliness
NOT in 1.0 but still on the long term roadmap is grid UI improvements , scripting and further expanding data sources.
March 2nd, 2023 by Ryan Hamilton
We’ve added a new tutorial and demo, creating a crytpo dashboard with QuestDB backend:
Pulse – Real-time interactive Dashboards 0.14.1 adds a Metrics Panel.
Allows tracking headline text while still showing the trend as a background chart.

March 2nd, 2023 by Ryan Hamilton
qStudio recently celebrated it’s tenth birthday and it’s still continuing to be the main IDE for many kdb+ developers. We want to keep making it better. Version 2.0 now includes
If you’ve been using qStudio, we would love to hear your feedback, please get in touch.
Download qStudio
February 16th, 2023 by Ryan Hamilton
This article is (part 2) of a series. See the previous post on “2018 – The Future of Tech in Banks, particularly within Market Data“.
The previous article described a few problems with the current tech/finance structure in most banks. In the words of Jim Barksdale:
“there are two ways to make money. You can bundle, or you can unbundle.”
In this case we can see two possible solutions:
- Horizontal Integration – Providing a bundled reliable layer e.g. AWS to solve your hardware needs
- Vertical Integration – Providing a front to back solution, SAAS – Software-As-A-Service e.g. github hosting, third-party trading platform.
Horizontal Integration AWS – To Solve hardware layer

Consider the example of outsourcing: “AWS for hardware”, it makes 100% sense, there is very little customization or unknown capability with 95%+ of servers for application use within a bank being fairly standard. The area where this currently becomes problematic is high-performance and co-location, to cover those needs hybrid-cloud could help. The benefits and savings in other areas, security/reliability/costs can often out weight the drawbacks. In my opinion most internal cloud solutions will dissapear within the next few years.
Benefits of Bundling/Outsourcing
Solutions rely on the problem being well known/understood and that all inputs/outputs to the bound box can be well defined. They work by:
- Preventing duplication of effort – Designed to be re-used
- Reducing communication overhead – Everything within their box is a service with APIs or configurable. No meetings/Change tickets required (OK less. There will always be change tickets!).
- Preventing misalignment and Misalignment of incentives -One entity is responsible for full delivery and if outsourced can be scaled up or down at little overhead/risk to the bank.
Vertical Integration – Outsourced Market Data-As-A-Service

An example of vertical integration would be “Market Data-As-A-Service”. If every bank has the same market data problem and we can get the benefits of buying that bundle, should we?
The danger is that it takes years to evolve to an “API” that covers 95% of the needs and even then you have to be careful that you don’t over allocate resources on something that the user actually has little value for. This is harder to know as an external entity as you don’t sit with the customer.
So given that banks have 3 options:
– Keep separate teams
– Use horizontal solutions
– Use vertical solutions
What should they do? When?
Ultimately it will be a combination of parts that evolve over time but if the problem is shared by all banks the solution is using off-the-shelf software eventually.
The market-data/feeds team should at all times be asking:
- Should we build this?
- Is this a problem specific to this bank that will add value?
- Or is it a general problem where we can take advantage of economies of scale?
Conclusion
Outsourced Solutions for Market Data – currently make less sense. As:
– Even if we can outsource storage of market data, we need a way to store our own trade date and other internal data sets.
– Column Oriented Storage – is becoming a commoditized technology. A number of firms including the major ones such as AWS are bringing user friendliness, reliability and general availability of what used to be a niche technology.
– Over recent years, firms including HFT have captured a lot of value by having in-depth market data knowledge.
The market data teams should begin to learn redshift/google/AWS solutions for as they scale to all firms everywhere the savings are massive.
Open Solutions
So far we mostly considered outsourced commercial solutions to solve the common problems. That however is not the only approach. It would be possible to reap the same, if not more benefits from an open core model. e.g. An open source trading system, that every bank makes commits to improve only keeping closed source the parts that are uniquely valuable to their business. Unfortunately in practice so far this seems to be less viable as any entity that pushes adoption of the platform, realizes costs pushing it while not capturing much value. Whereas closed source, the company incurs the marketing costs but can get this back in licensing fees.