Archive Page 4
May 22nd, 2023 by Ryan Hamilton
- kdb now on AWS – kdb as a fully managed service under finspace – The website says available in June but at least one big investment bank is trialling it and having talked to a representative at AWS a significant amount of work and effort has gone into this. This is great to see. I think for the future of KX this needs to work. It doesn’t make sense for every firm to reinvent the wheel, banks could afford to do it but smaller firms cannot.
- kdb.ai – seems to be repositioning kdb as a vector database for AI – currently it’s a few blog posts, whether there’s a real product or it’s to ride the AI hype train we will have to wait and see. Given the hype other inferior databases have received in the past, kdb deserves some attention.
- Run q code on Snowflake – Snowflake is a column oriented database that only runs in the cloud and uses a central storage with compute nodes to service SQL queries. They provide snowpark that allows running java, python and now q close to the data. I’m unsure who the target of this is, many users struggle to fully understand one database without inception.
Additionally kx:
- announced PyKX will be open source?? (exact details to be confirmed, as repo is not available today 2023-05-21)
- PyKX may add the ability to act as a very fast event processor
- Announced improved vs code support will arrive shortly
- The Core team demoed some really cool functionality, I’m not sure it was all meant to be public so I will just say some parts were similar to Destructuring Assignment in javascript.
April 28th, 2023 by Ryan Hamilton
Are you a Quant or kdb Developer struggling to get the UI team to work on your app?
With Pulse, you can now build interactive data tools fast by yourself.
Pulse version 1.0 is available to download now and allows you to build real-time interactive data apps, free for up to 3 users.
After an intense year working closely with groups of quants and data analysts, with releases every week, Pulse has reached a major milestone.
Pulse 1.0 is being used successfully to deliver data apps including:
- TCA – Transaction Cost Analysis
- Algo start/stop and limit controls
- Trade Blotters that update in real-time
- Live Price Charts
Find Out More
Pulse now provides:
A massive thanks to the many beta testers, early adopters, users and companies that invested in and purchased Pulse.
Particular thanks to Rahul, Ruairi, Ian, Steve, Chris, WooiKent, Franco, Palmit, JP, JD, PN, SG, JM, KF, AR, MC, JC, CA, SS. Thanks for raising numerous feature requests and providing excellent feedback that helped make Pulse what it is today.
If you want to hear more, join one of our scheduled demos or contact us.
If you tried an old version or if you have never tried Pulse:
Download Pulse Now
March 27th, 2023 by John Dempster
qStudio release 2.05 added:
- Mac / Intellij / Flat / Material Theme support
- Inlcuding 20+ Intellij and 20+ Material Themes builtin
- Scaling font size in settings increases code size and all font sizes throughout the UI
- Jetbrains Mono is now bundled as the default Font for development
Notice Also
- The menu bar is now integrated with the title on platforms with that enabled (Windows 10/11)
- File chooser now includes shortcuts to popular locations
- Native window decorations on Windows 10 – Snapping / Shadows / etc.
qStudio Dark Theme
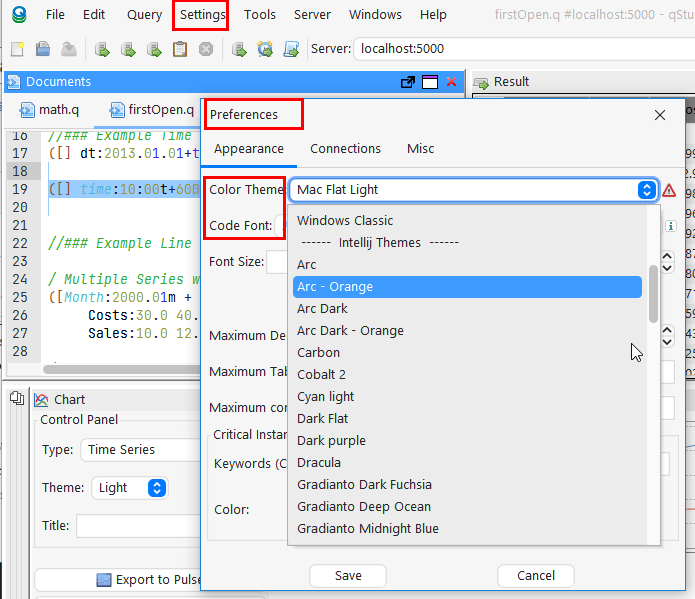
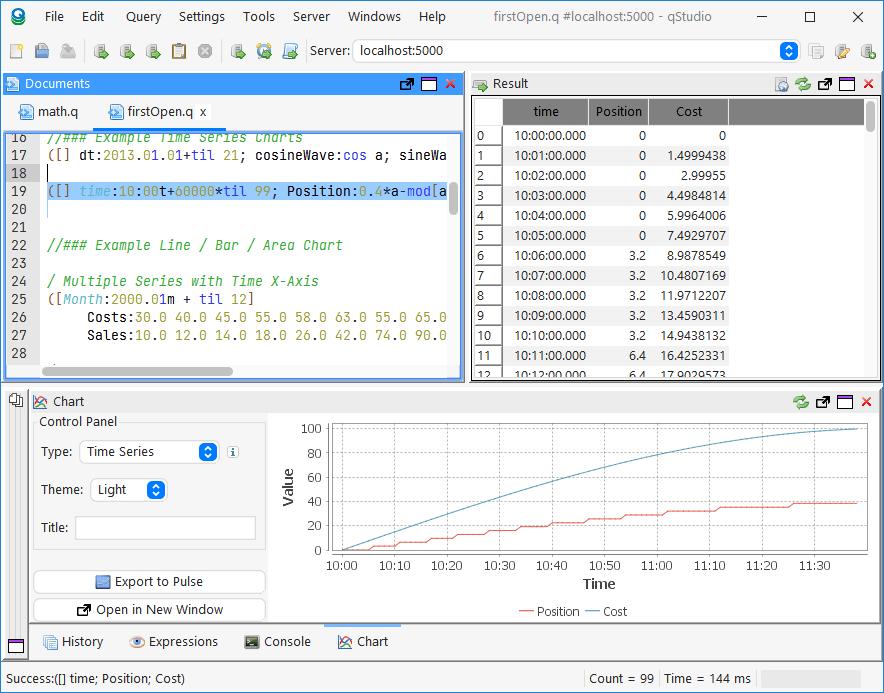
qStudio Light Mac Theme
March 24th, 2023 by John Dempster
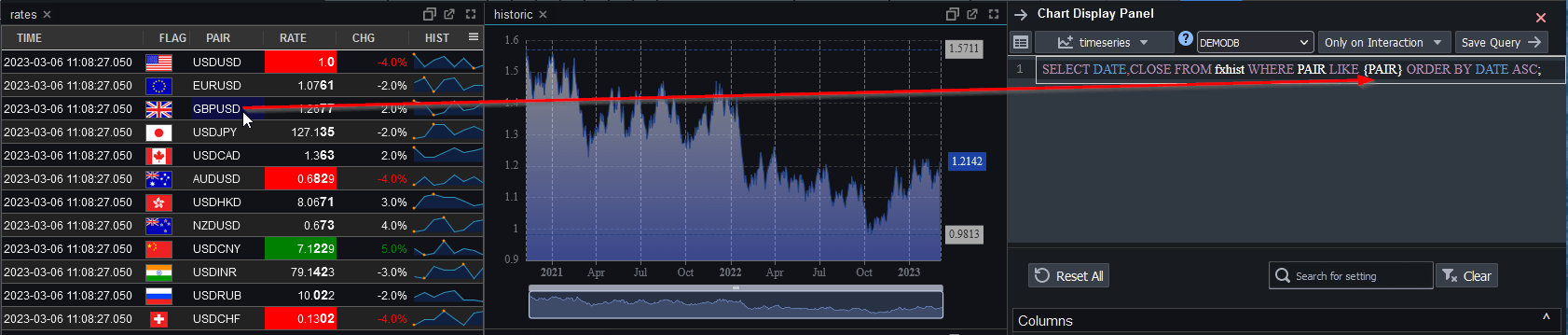
Linked Tables and Charts
Since our last blogged release our biggest new feature is Linked Tables and Charts.
When a user clicks on a table or chart, it populates variables that can be used within other charts and tables.
One very creative user already used this to create tableA that when clicked populates tableB, that when click populates tableC and so on 4 levels deep.
Click the image below to see details and to find a tutorial video.
Stability
With increasing users comes more edge cases that are hard to predict in advance. We’ve invested a lot in stability in the last 2 months, not all of which will be immediately visible. One hotspot involved a number of issues related to websockets including internal firewall rules, cloudflare websocket timeouts and slow subscribers. One of the more interesting changes was introducing a heartbeat on the websocket to prevent timeouts, we then reused that heartbeat to detect slow subscribers for example when someone moves a tab to the background or minimizes their browser. We now smartly throttle back their querying until they catch up or bring the browser back to being visibile. We’ve addressed all known issues and added a number of stress testing test runs to ensure they always continue to work in future.
REST API
Lastly, some of our advanced kdb users spin up dynamic processes for users. They wanted to make those servers available in Pulse.
We’ve added a REST API to allow setting servers dynamically using a API keys.
March 14th, 2023 by Ryan Hamilton
0.6.5 release in July 2022
For our initial release of Pulse we had 4 essential use cases that we solved. This included:
- Trade Blotter – Scrolling real-time table of trades.
- TAQ – Trade and Quote graph of teal-time quotes
- A live updating current price table with color highlighting.
- A simple time-series graph to plot single metrics. e.g. mid price over time.
1.0 Release March 2023
Pulse is a tool for real-time interactive dashboards.
Over the last few months we focussed on adding new visualizations , allowing charts/tables to be customized and supporting QuestDB.
The goal for 1.0 is:
- Increased Interactivity – To allow user interaction
- Support for large deployments
- Dynamically updating data sources – For when db server deployments can change host/port
- Licensing – builtin
- Reporting tools – to show current and historical dashboard usage
- Possible custom connection to user to allow security.
- Stability
- Warn when dashboard is growing very large
- websocket heartbeat to prevent idle disconnects
- Improved User Friendliness
NOT in 1.0 but still on the long term roadmap is grid UI improvements , scripting and further expanding data sources.
March 2nd, 2023 by Ryan Hamilton
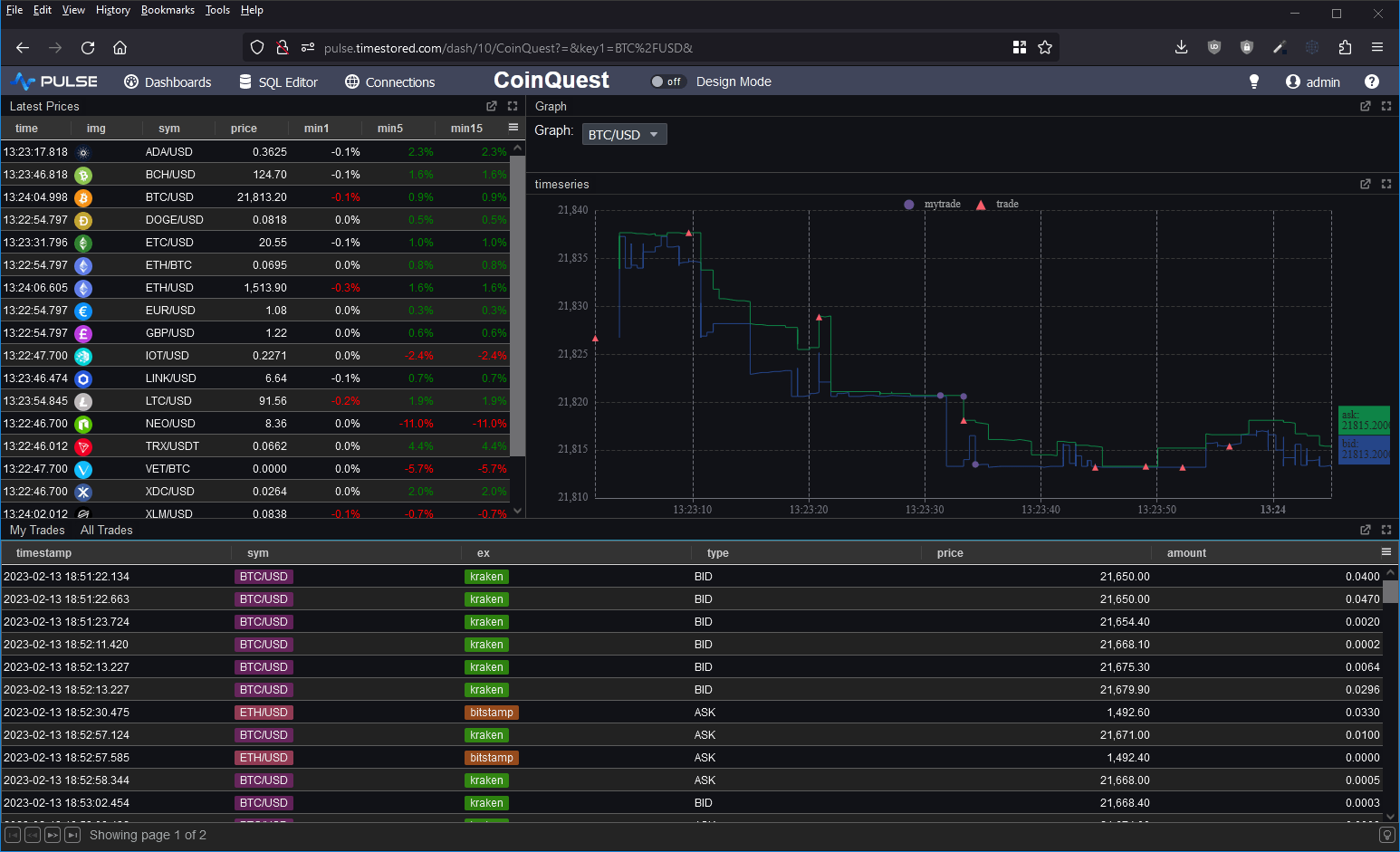
We’ve added a new tutorial and demo, creating a crytpo dashboard with QuestDB backend:
Pulse – Real-time interactive Dashboards 0.14.1 adds a Metrics Panel.
Allows tracking headline text while still showing the trend as a background chart.

March 2nd, 2023 by Ryan Hamilton
qStudio recently celebrated it’s tenth birthday and it’s still continuing to be the main IDE for many kdb+ developers. We want to keep making it better. Version 2.0 now includes
If you’ve been using qStudio, we would love to hear your feedback, please get in touch.
Download qStudio
February 16th, 2023 by Ryan Hamilton
This article is (part 2) of a series. See the previous post on “2018 – The Future of Tech in Banks, particularly within Market Data“.
The previous article described a few problems with the current tech/finance structure in most banks. In the words of Jim Barksdale:
“there are two ways to make money. You can bundle, or you can unbundle.”
In this case we can see two possible solutions:
- Horizontal Integration – Providing a bundled reliable layer e.g. AWS to solve your hardware needs
- Vertical Integration – Providing a front to back solution, SAAS – Software-As-A-Service e.g. github hosting, third-party trading platform.
Horizontal Integration AWS – To Solve hardware layer

Consider the example of outsourcing: “AWS for hardware”, it makes 100% sense, there is very little customization or unknown capability with 95%+ of servers for application use within a bank being fairly standard. The area where this currently becomes problematic is high-performance and co-location, to cover those needs hybrid-cloud could help. The benefits and savings in other areas, security/reliability/costs can often out weight the drawbacks. In my opinion most internal cloud solutions will dissapear within the next few years.
Benefits of Bundling/Outsourcing
Solutions rely on the problem being well known/understood and that all inputs/outputs to the bound box can be well defined. They work by:
- Preventing duplication of effort – Designed to be re-used
- Reducing communication overhead – Everything within their box is a service with APIs or configurable. No meetings/Change tickets required (OK less. There will always be change tickets!).
- Preventing misalignment and Misalignment of incentives -One entity is responsible for full delivery and if outsourced can be scaled up or down at little overhead/risk to the bank.
Vertical Integration – Outsourced Market Data-As-A-Service

An example of vertical integration would be “Market Data-As-A-Service”. If every bank has the same market data problem and we can get the benefits of buying that bundle, should we?
The danger is that it takes years to evolve to an “API” that covers 95% of the needs and even then you have to be careful that you don’t over allocate resources on something that the user actually has little value for. This is harder to know as an external entity as you don’t sit with the customer.
So given that banks have 3 options:
– Keep separate teams
– Use horizontal solutions
– Use vertical solutions
What should they do? When?
Ultimately it will be a combination of parts that evolve over time but if the problem is shared by all banks the solution is using off-the-shelf software eventually.
The market-data/feeds team should at all times be asking:
- Should we build this?
- Is this a problem specific to this bank that will add value?
- Or is it a general problem where we can take advantage of economies of scale?
Conclusion
Outsourced Solutions for Market Data – currently make less sense. As:
– Even if we can outsource storage of market data, we need a way to store our own trade date and other internal data sets.
– Column Oriented Storage – is becoming a commoditized technology. A number of firms including the major ones such as AWS are bringing user friendliness, reliability and general availability of what used to be a niche technology.
– Over recent years, firms including HFT have captured a lot of value by having in-depth market data knowledge.
The market data teams should begin to learn redshift/google/AWS solutions for as they scale to all firms everywhere the savings are massive.
Open Solutions
So far we mostly considered outsourced commercial solutions to solve the common problems. That however is not the only approach. It would be possible to reap the same, if not more benefits from an open core model. e.g. An open source trading system, that every bank makes commits to improve only keeping closed source the parts that are uniquely valuable to their business. Unfortunately in practice so far this seems to be less viable as any entity that pushes adoption of the platform, realizes costs pushing it while not capturing much value. Whereas closed source, the company incurs the marketing costs but can get this back in licensing fees.
February 6th, 2023 by Ryan Hamilton
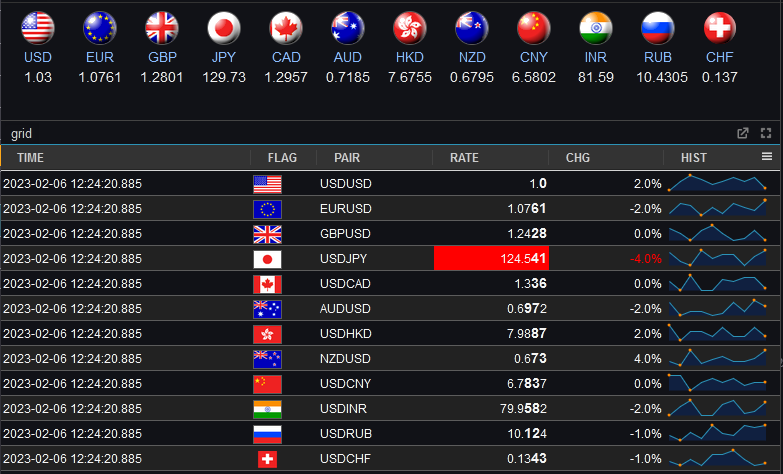
Pulse – Real-time interactive Dashboards 0.13.5 adds Sparkline and Dynamic HTML support
- Dynamic HTML – Full user control to generate HTML using template languages
- Sparklines – Embed small charts within a table by specifying nested arrays.
DOWNLOAD NOW

Pulse is designed to provide real-time interactive dashboards so the underlying database has to be really fast. Pulse can support almost any data source, the question is which databases are worth supporting.
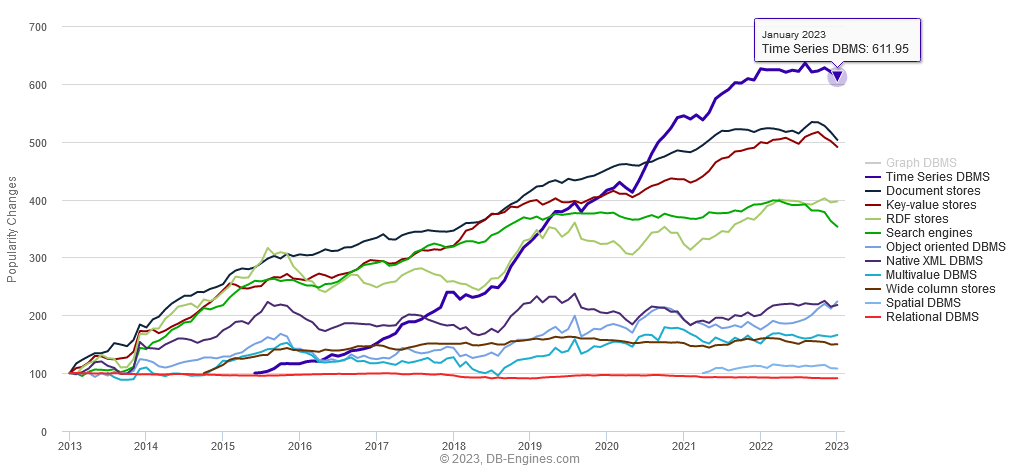
Time-series databases are the fastest growing database sector (image below).
The great news is that in the last few years there has been a a lot of interesting new entrants. So we’ve updated our past articles:
- Top Column-Oriented Databases – DuckDB, Clickhouse and Doris are the new exciting entrants. Benchmark results in article.
- Top Time-Series Databases – Have exploded in popularity. QuestDB and TimeScale are the new entrants there. Benchmark results in article.
January 23rd, 2023 by John Dempster
It’s a New Year, traditionally the time to consider a potential job change.
To help your search we have: